接下来,我们来点有趣的:让 OpenAI API 联网搜索,并返回答案。这里我们需要借助 Serpapi 来实现,Serpapi 提供了 Google 搜索的 API 接口。
首先,我们需要到 Serpapi 官网上注册一个用户,并复制生成的 API key。然后像设置 OpenAI API key 一样设置到环境变量中。
1 2 3
import os os.environ["OPENAI_API_KEY"] = '你的api key' os.environ["SERPAPI_API_KEY"] = '你的api key'
接下来,编写代码:
1 2 3 4 5 6 7 8
from langchain.agents import load_tools, initialize_agent from langchain.llms import OpenAI from langchain.agents import AgentType
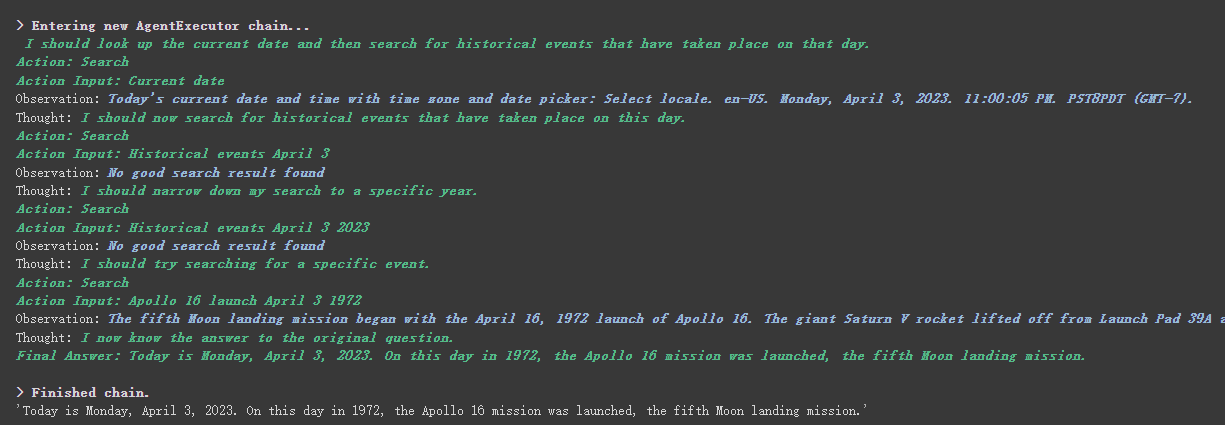
llm = OpenAI(temperature=0, max_tokens=2048) tools = load_tools(["serpapi"]) agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) agent.run("What's the date today? What great events have taken place today in history?")
我们可以看到,他正确返回了日期,并且列出了历史上的今天发生的重大事件。
3. 对超长文本进行总结
假如我们想用 OpenAI API 对一段文本进行总结,但文本超过了 API 最大的 token 限制,这时我们可以使用 LangChain 来处理。
LangChain 会自动分段并总结每段内容,最后再进行一次总体总结。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from langchain.document_loaders import UnstructuredFileLoader from langchain.chains.summarize import load_summarize_chain from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain import OpenAI
在这个例子中,我们将介绍如何从本地读取多个文档构建知识库,并使用 OpenAI API 在知识库中进行搜索并回答问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import CharacterTextSplitter from langchain import OpenAI from langchain.document_loaders import DirectoryLoader from langchain.chains import RetrievalQA
import os from langchain.document_loaders import YoutubeLoader from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chains import ConversationalRetrievalChain from langchain.chat_models import ChatOpenAI from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
system_template = """ Use the following context to answer the user's question. If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese. ----------- {question} ----------- {chat_history} """
from langchain.llms import OpenAI from langchain.agents import initialize_agent from langchain.agents.agent_toolkits import ZapierToolkit from langchain.utilities.zapier import ZapierNLAWrapper