Vidu1.5:全球首个多主体一致性文生视频大模型来了!
就在昨天,生数科技推出了其最新AI视频生成版本:vidu1.5,号称全球唯一支持多主体一致性的文生视频大模型!目前其他主流AI文生视频:pika、runway等都只能确保一个角色、物体和场景的一致性,vidu1.5是全球首发支持多主体一致性的模型,接下来,**我们详细看下vidu1.5多主体一致性生成的视频效果如何**!
vidu1.5视频模型升级功能有哪些?
主要升级点如下:
- 参考生视频支持多主体:全球首发多主体一致性功能,让您创作的角色、物体、场景等始终保持一致。
- 生成质量提升:视频画面更加稳定,细节丰富,清晰度显著提高,支持极速、720p及1080p三种清晰度选项。
- 语义理解增强:模型对复杂提示的理解能力进一步提升,同时可理解多种镜头语言,包括运镜、视角、构图以及特殊拍摄手法等。
- 运动幅度控制:您可自由调节视频中的运动幅度。
- 动漫风格扩展:支持更多2D平面动画风格,丰富您的创作选择。
使用vidu1.5实现文生视频操作步骤
1、登录vidu官网
官网地址:https://www.vidu.studio/zh
点击右上角立即体验可以直接使用谷歌登录,未注册用户会自动完成注册并登录
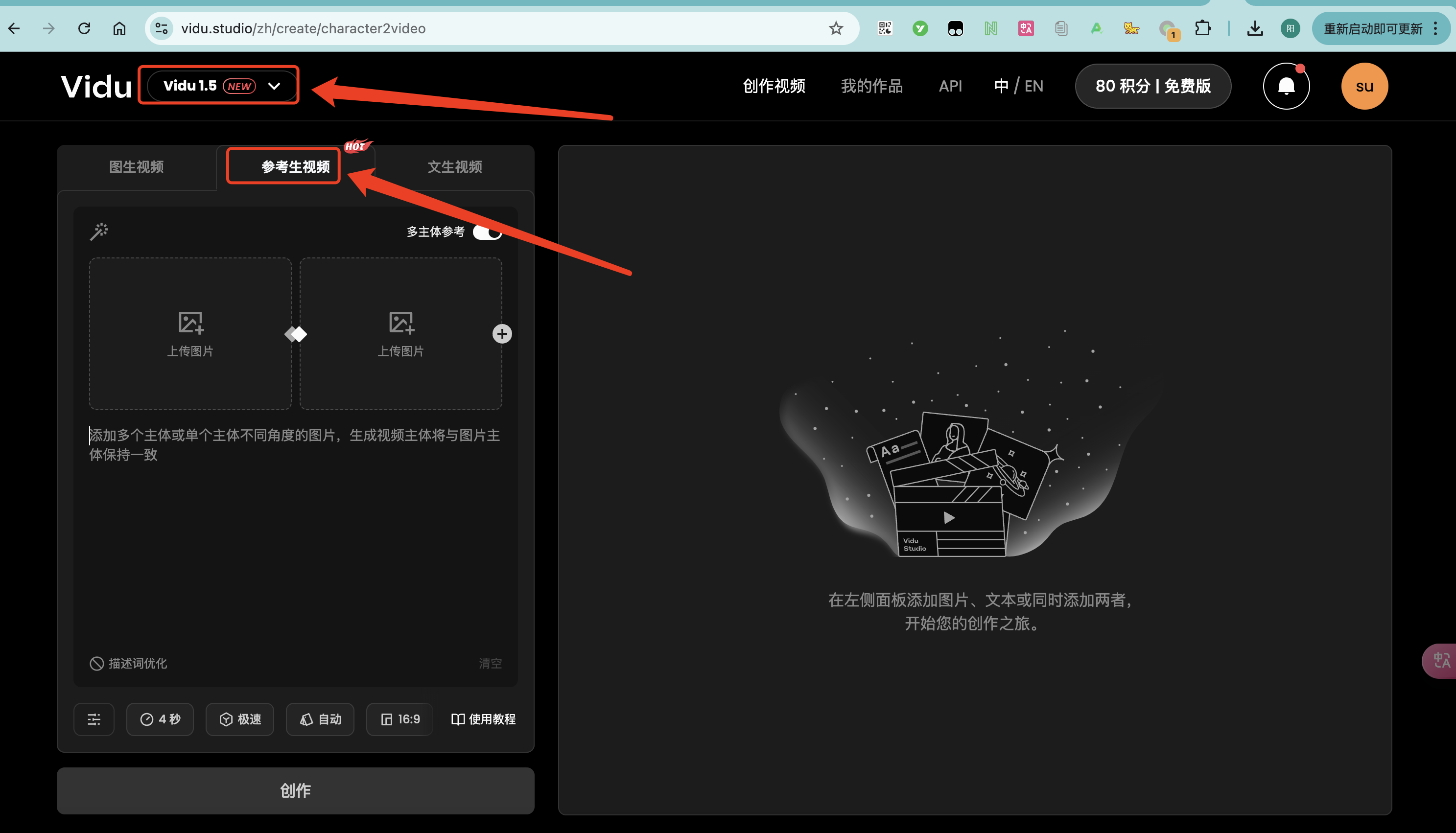
2、选择vidu1.5模型
左上角选择vidu1.5模型,勾选多主体参考生视频
3、上传多主体图片并添加提示词
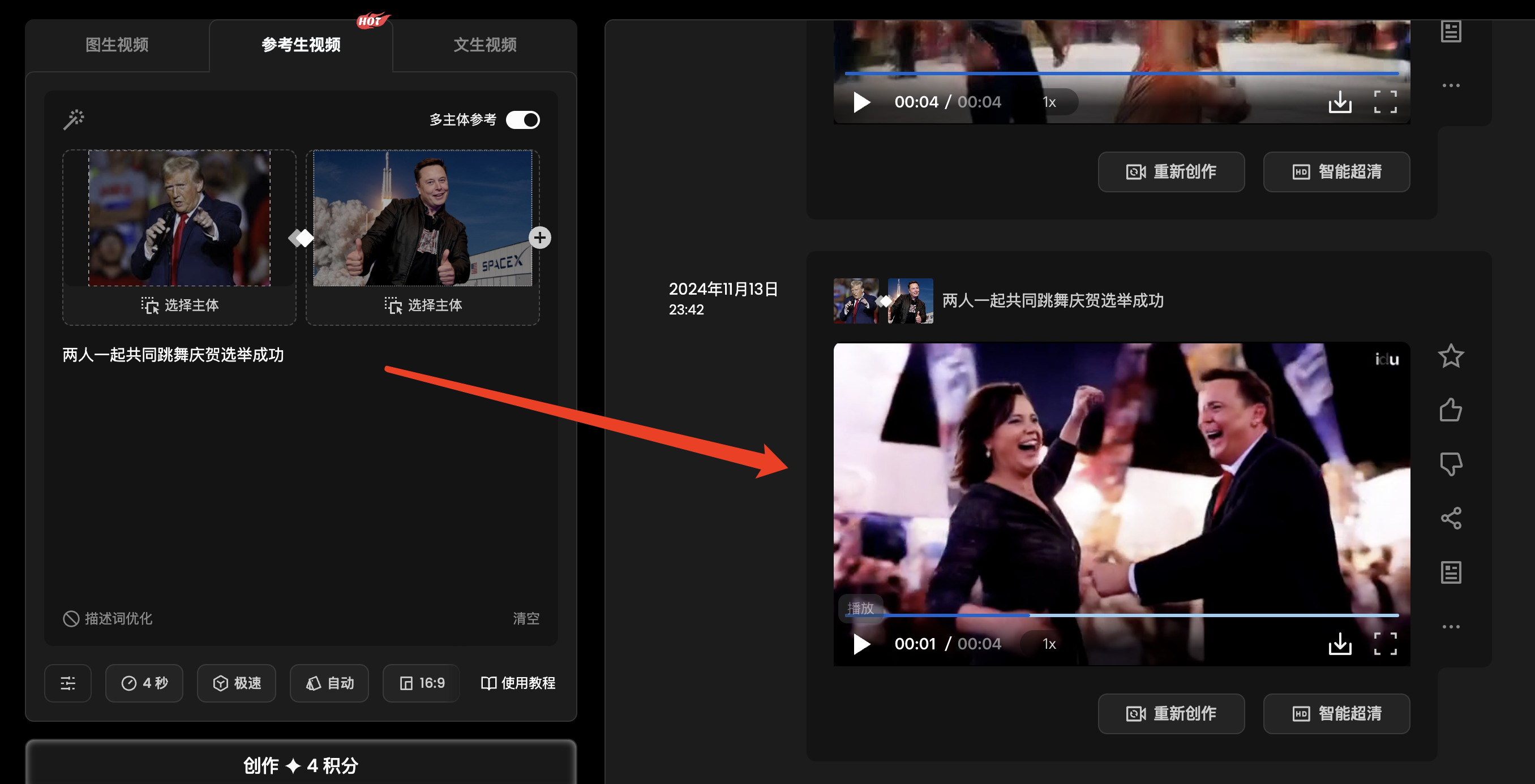
上传个当前比较热门的两个人物图片,再加上提示词
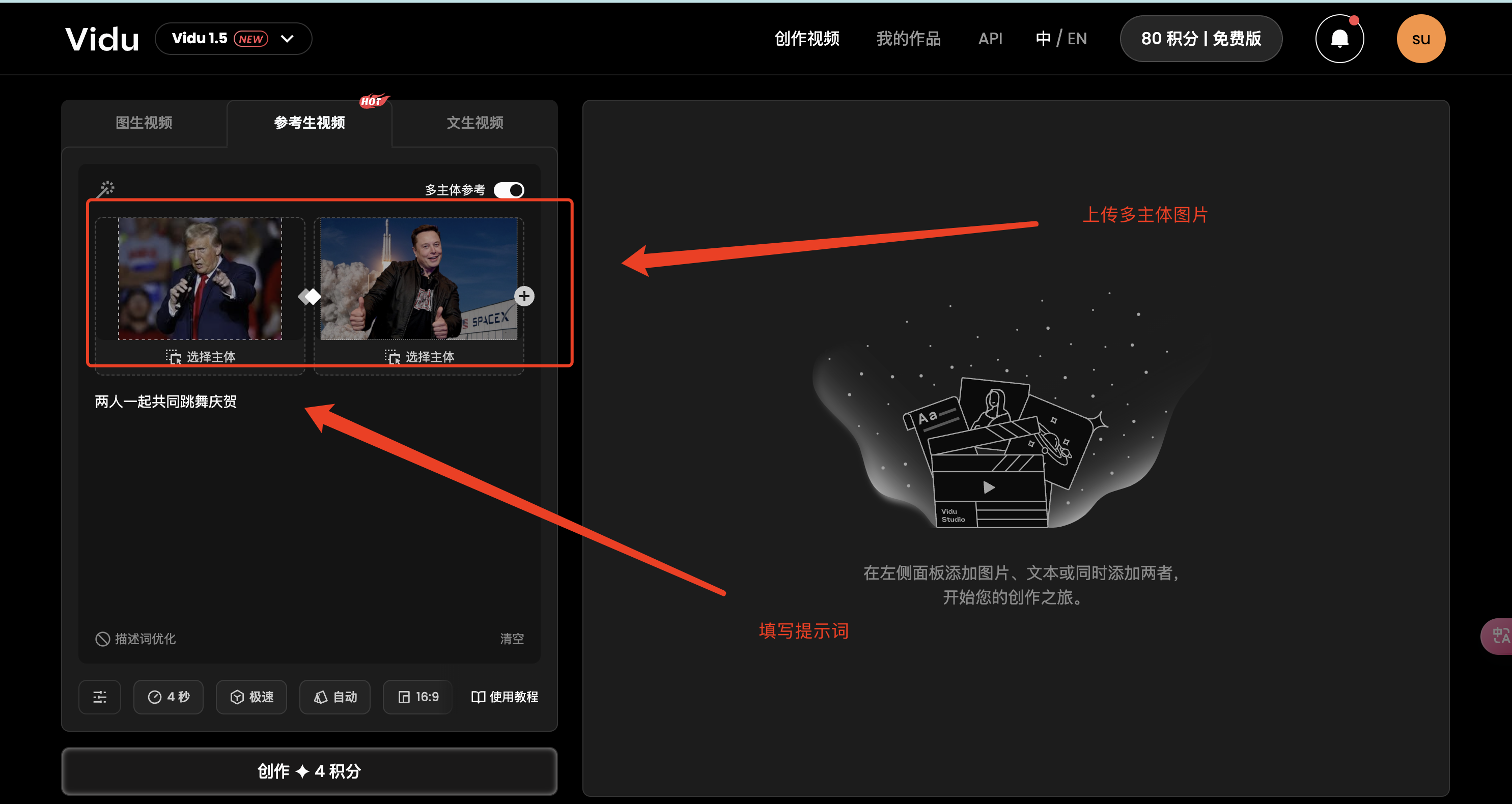
主体图一:

主体图二:

生成效果(说实话:有点一言难尽):大家可以自己尝试试下,图片已给出
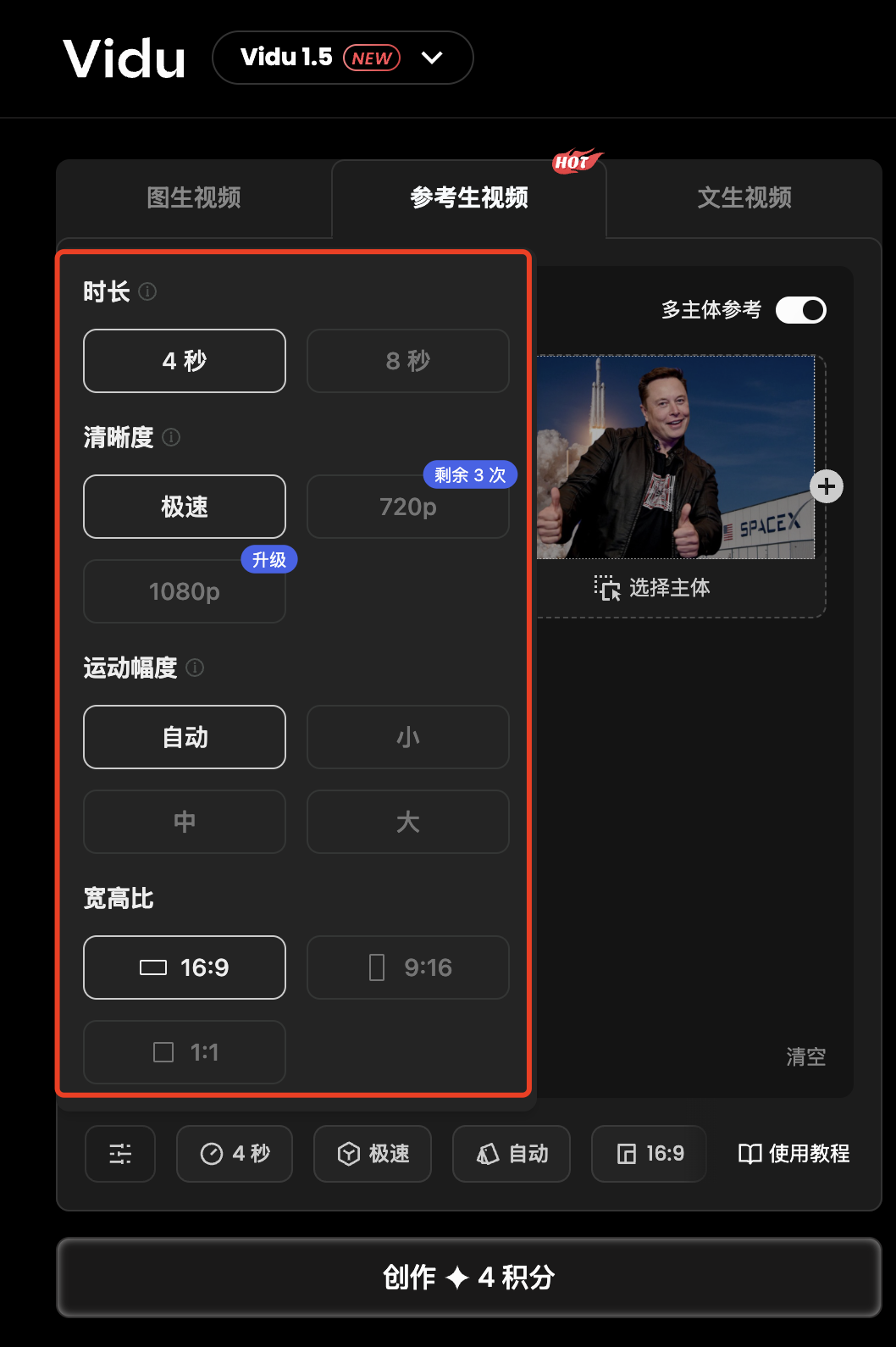
4、支持视频风格
目前支持时长、清晰度、运动幅度、宽高比四个维度的设置
提示词分析
从实测看,简单提示词生成的效果比较差,当提示词遵循主体/场景(主要指具体内容),场景描述,环境描述和艺术风格/媒介的基本结构时,可以在一定程度上提升视频生成效果。
以“柯基犬游泳”为例
优秀的提示词:
Capture a serene moment featuring a baby Corgi swimming gracefully in a large, sunlit pool. The underwater perspective showcases the puppy, its gentle smile illuminated by soft, golden hour lighting that filters through the water, creating a dance of light and shadow on the pool’s bottom. The scene is set in soft pastel colors, enhancing the dreamlike, ethereal quality of the atmosphere. The high-resolution photography captures every delicate detail of the water’s texture and the Corgi’s joyful expression, creating a simple yet cinematic portrait of tranquility and innocence. This minimalist yet emotive setup conveys a sense of calm and happiness, ideal for a serene and visually captivating film sequence.
对应中文:
捕捉柯基犬宝宝在阳光照耀下的大泳池中优雅游泳的宁静时刻。水下的视角展现了小狗温柔的笑容,柔和的金色灯光穿过水面,在池底形成光影的舞动。场景以柔和的粉色为主色调,烘托出梦幻般的空灵氛围。高分辨率的摄影作品捕捉到了水的纹理和柯基犬欢快表情的每一个精致细节,创造出一幅简单而又充满电影感的宁静和纯真的肖像。这种简约而富有情感的设置传达出一种平静和幸福的感觉,是宁静而具有视觉吸引力的电影镜头的理想选择。
可以得到效果:

目前主流AI视频更新内容比较
除Vidu外,自今年9月份以来,据不完全统计,包括字节旗下即梦AI、快手可灵AI、Runway、智谱清影、爱诗科技PixVerse、Pika等主流的AI视频生成平台,都已经进行了版本更新。
| 公司 | 平台 | 更新日期 | 更新内容 | 底层大模型 |
|---|---|---|---|---|
| 智谱AI | 清影 | 2024年11月8日 | 10秒时长、4k、60帧视频编辑调整、任意尺寸、音画重制,以及更好人体动作和物理世界模拟 | GLM-4模型CogSound音乐模型 |
| 生数科技 | vidu | 2024年11月13日 | 视频转图片(JPG/PNG),支持多个主题风格的生成,全球最先实现多主体一致性视频生成 | 视频风格模型vidu |
| 字节跳动 | 即梦AI | 2024年11月8日 | 全新模型S2.0,通过几句话就可生成高质量图片及视频,生成视频“动作更流畅、自然” | 豆包视频模型S2.0 |
| 快手 | 可灵AI | 2024年9月20日 | 可灵1.5版本,接入了新一代模型,画质和动态质重都 大幅提升、会员还不加价升1080P画质,原有的模型也加入了新功能:运动笔刷 |
文生图大模型,可灵大模型(Kling) |
| 爱诗科技 | PixVerse | 2024年10月29日 | Pixverse V3版本,新版本在底层模型能力大幅提升,同时提供创意模板、口型匹配、故事续写和风格转换等多模态生成能力 | 视频生成模型PixVerse |
| Runway | Runway | 2024年11月5日 | 可将真人面部表情精确复刻给AI角色,以实现3D化的AI摄像头控件 | Gen-3 Alpha |
| MinMax | 海螺AI | 2024年10月9日 | 在文本控制方面能力突出,尤其在人物表情、运镜,多镜头生成方面表现优异 | 视频模型abob-video-1 |
| PIKA | PIKA | 2024年10月10日 | 新增了爆炸、压扁、溶解、膨胀等四大特效,为图片增加了很多生动的动态效果 | pika1.0 |
vidu涉及到的技术有哪些
Vidu 1.5采用了以下技术:
- 多模态学习:整合视觉、文本和声音等信息源,处理不同形式的数据。
- Diffusion与Transformer融合架构:结合了Diffusion模型和Transformer模型的优势,提升了视觉任务的效率和能力。
- 语义理解:精准解析用户的文本描述或指令,确保生成的视频符合创意意图。
使用场景与目标用户
Vidu 1.5适用于多个行业和场景:
- 影视制作:用于电影和电视剧的预制作,帮助预览和优化角色设计。
- 动漫创作:支持丰富的动漫风格,激发多元创作。
- 广告制作:定制个性化的创意广告内容,突出品牌风格。
- 社交媒体内容创作:为社交媒体平台制作一致角色形象的视频内容,增强观众认同感。
总结
当前,像Vidu和智谱清影这样的AI视频生成平台在主体一致性、人物稳定性以及视频生成时长等方面不断取得进展。然而,它们尚未在市场上形成独特的赛道和竞争优势。
目前,主流的AI视频工具仍处于竞争激烈的阶段。大多数工具功能单一,需要结合多种不同的视频创作工具才能生成可直接用于商业化的视频。
展望未来,AI视频生成大模型平台需要持续迭代和进化,以提升其技术水平和市场竞争力。