手把手教你本地部署DeepSeek R1,让你AI性能原地起飞
随着人工智能技术的迅猛发展,越来越多的人开始关注并使用AI协助完成工作了,DeepSeek便是今年最火的一款大语言模型,目前使用DeepSeek的方式有三种:
- 使用已部署了网页版的AI平台
- 使用云服务商提供的API接口,对接到套壳AI平台上使用
- 自己本地搭建R1模型
接下来,我将详细讲解下这三种方式的主流媒体有哪些,本次重点是讲第三个:**如何本地搭建DeepSeek R1模型**
1、使用网页版DeepSeek
目前市面上,能部署出满血版的DeepSeek R1的平台不多,主要是它最低配需要8张96G显存太费钱了!不过这些对于那些大型科技公司来说倒不是什么难题,目前已支持网页版满血DeepSeek R1模型的平台主要有:**DeepSeek官网、天工AI、秘塔AI、纳米AI、超算互联网平台、问小白**
1.1、DeepSeek官网
官网地址:https://chat.deepseek.com/
这个大家应该很熟悉了,最正宗的官网页面,支持R1及深度思考
好用归好用,就是经常服务器访问不通
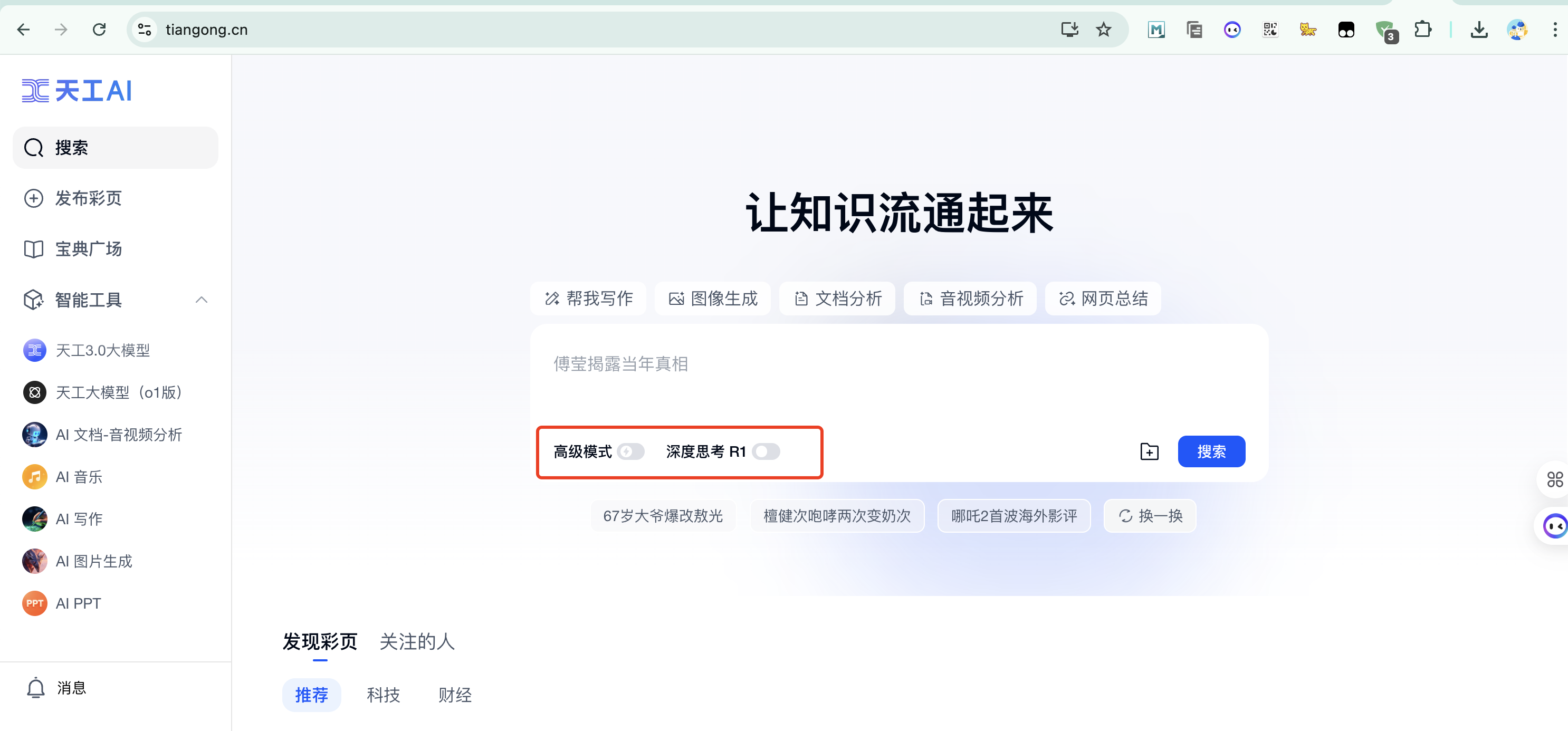
1.2、天工AI
昆仑万维旗下产品
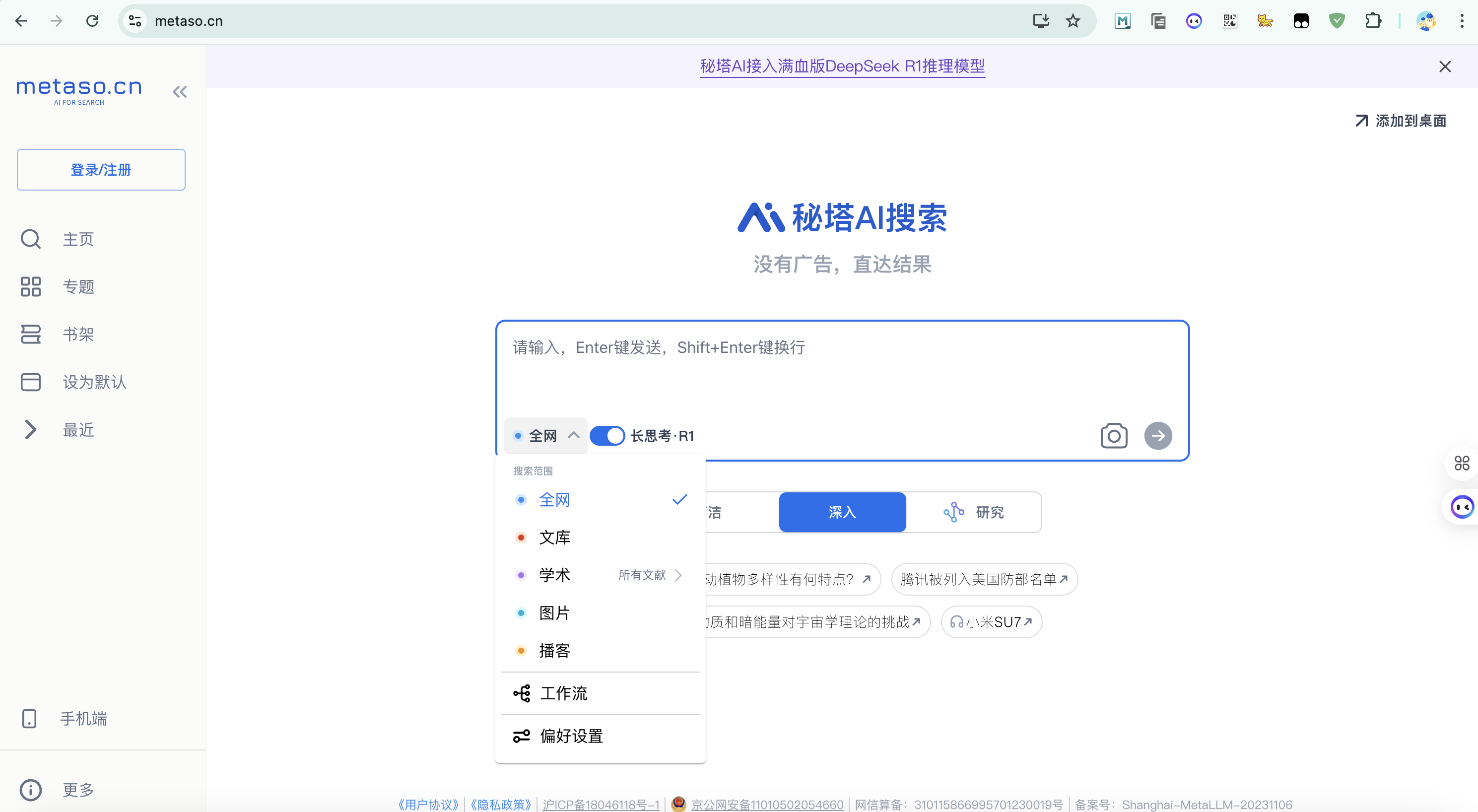
1.3、秘塔AI
官网地址:https://metaso.cn/
接入了满血版 DeepSeek R1(671B)推理模型,每个账号每天有 100 次搜索额度,并支持联网功能,操作便捷。
1.4、纳米AI
官网地址:https://www.n.cn/
360出品,手机端网页端均可用
1.5、超算互联网平台
官网地址:https://chat.scnet.cn/#/home
已推出 DeepSeek-R1 模型的 7B、32B及满血版671B 版本, 平台目前免费开放。
1.6、POE
官网地址:https://poe.com/
一款AI产品聚合平台,价格有点小贵,不差钱的可以去用
1.7、问小白
官网地址:https://www.wenxiaobai.com/
问小白平台上周也刚上线了DeepSeek-R1满血版,提供免费流畅的使用体验。支持联网搜索、上传文件、多模态分析等功能,具备深度思考、时效性回答、生成深度话题等亮点。客户端支持语音输入和语音播放,适合多群体使用。
1.8、圈友互联AI
地址:https://ai.quanyouhulian.com/
哈哈,这个是我自己的AI平台,目前已对接了主流的AI平台,DeepSeek R1满血版也还在对接中,对接完成将会免费开放出来,另外里面的AI音乐、AI视频均为当前最强模型!
2、使用云服务商提供的API接口
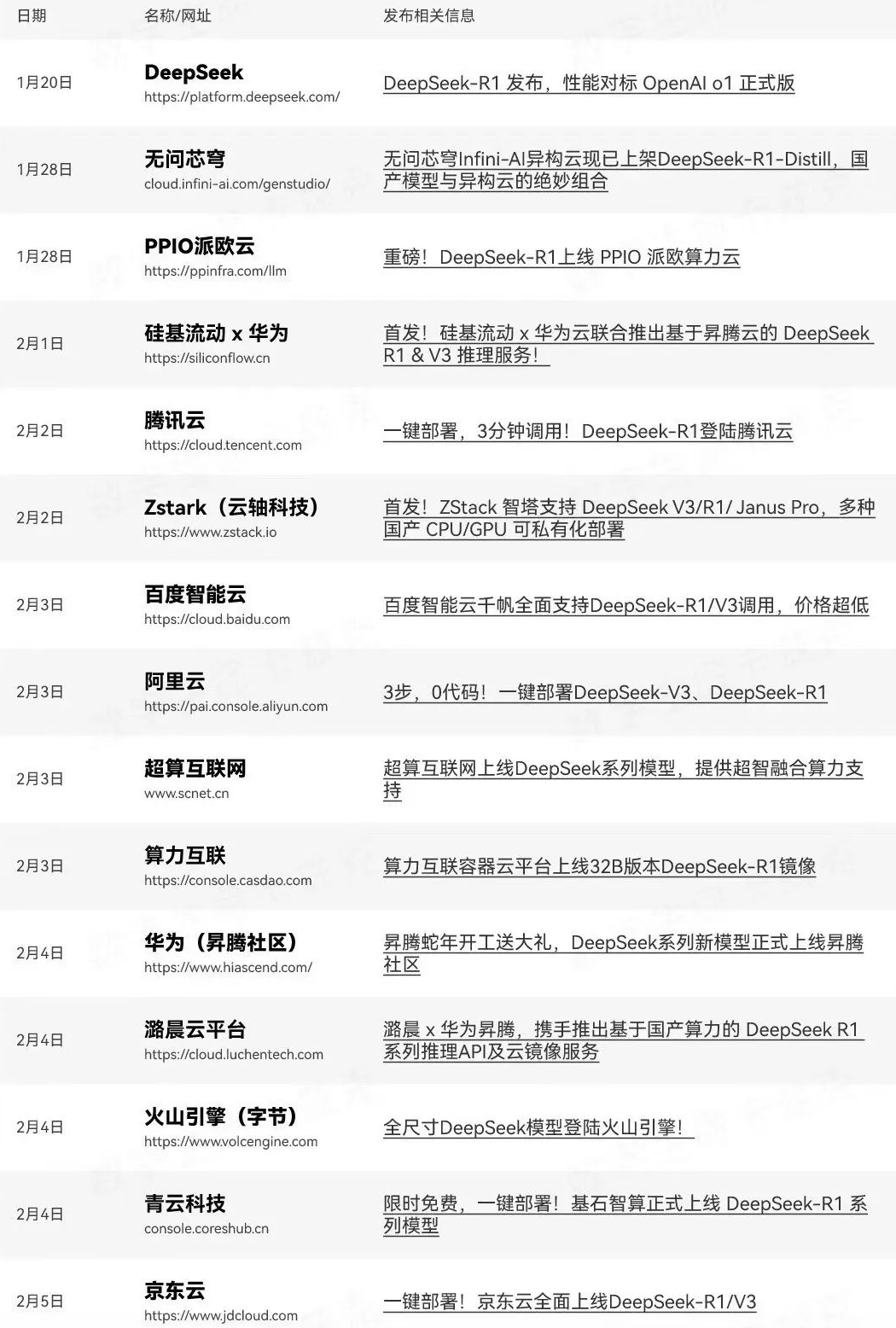
这个之前文章讲过,主要拿到API接口后放到个套壳AI前端使用,这里就不重复将了,目前已支持提供API的服务厂商如下
3、自己本地搭建R1模型
好了,前面讲了一大堆废话,重点干货现在来了!
为什么要选择本地部署DeepSeek?
原因很简单:DeepSeek的服务器因访问量过大,现在服务经常卡顿,本地部署能够确保你在任何时候都可以使用该模型。此外,本地部署还能提升数据的安全性,避免敏感信息的外泄。**特别是对于需要连接私有接口(比如:使用AI炒股、使用AI做预测)**,本地部署将是唯一选择!
本地部署DeepSeek R1需要什么配置?
我想这个问题大家都很关心,先来看下R1都有哪些开源的模型,这里我们去Hubgging Face(AI界的Github):https://huggingface.co/models?sort=trending&search=Deepseek 可以看到R1有很多蒸馏版的小参数模型(科普下:蒸馏版意思就是使用别的大模型的答案去做的参数训练)
再来看下官网给出的最低配置要求,可以看出满血版最低需要8 * 96G的显存,这个配置我问了下阿里云,每个月要15万,所以大家别想了,咱们本地就使用DeepSeek-R1-Distill-Qwen-1.5B就可以了
| 模型 | 最低配置 | 支持的最大Token数 | ||
|---|---|---|---|---|
| 部署方式为BladeLLM加速(推荐) | 部署方式为vLLM加速 | 部署方式为标准部署 | ||
| DeepSeek-R1 | 8卡GU120(8 * 96 GB显存) | 不支持 | 4096 | 不支持 |
| DeepSeek-V3 | 8卡GU120(8 * 96 GB显存) | 不支持 | 4096 | 2000 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1卡A10(24 GB显存) | 131072 | 131072 | 131072 |
| DeepSeek-R1-Distill-Qwen-7B | 1卡A10(24 GB显存) | 131072 | 32768 | 131072 |
| DeepSeek-R1-Distill-Llama-8B | 1卡A10(24 GB显存) | 131072 | 32768 | 131072 |
| DeepSeek-R1-Distill-Qwen-14B | 1卡GPU L(48 GB显存) | 131072 | 32768 | 131072 |
| DeepSeek-R1-Distill-Qwen-32B | 1卡GU120(96 GB显存) | 131072 | 32768 | 131072 |
| DeepSeek-R1-Distill-Llama-70B | 2卡GU120(2 * 96 GB显存) | 131072 | 32768 | 131072 |
如何在本地部署?
目前本地快捷部署主要有两种方式:Ollama、LM Studio,接下来我将重点讲下如何使用Ollama部署
1、下载Ollama
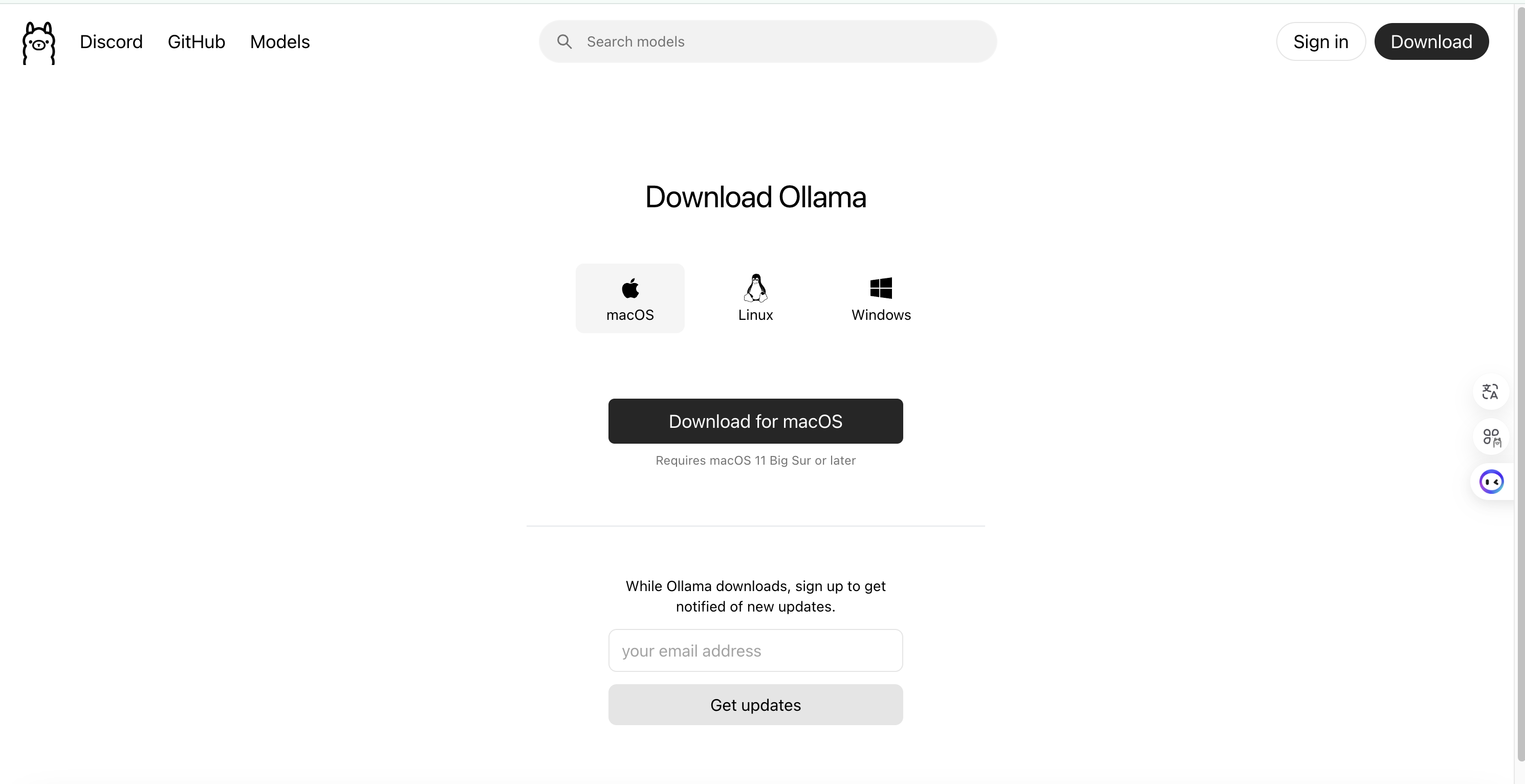
官网地址:https://ollama.com/
Ollama是一个专门用来本地运行开源大模型的工具,目前也是开源模型部署使用最多的平台
选择你电脑对应的版本
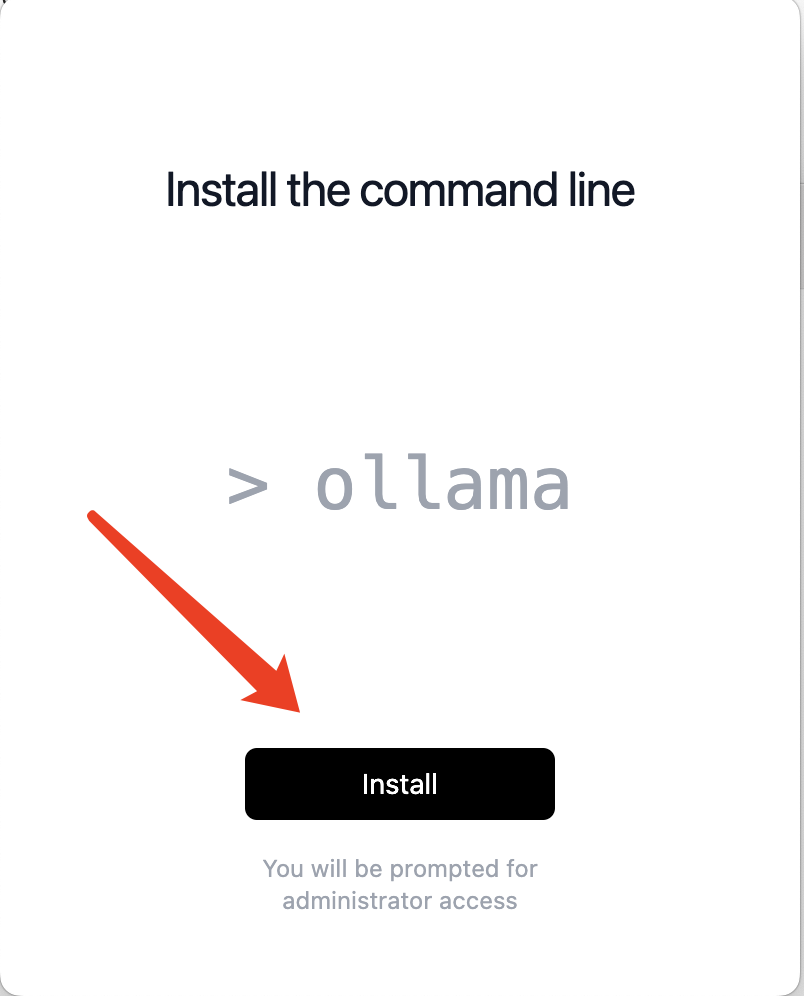
下载完成后点击Install即可自动完成安装
验证安装版本
进入终端输入命令,验证是否安装成功
1 | |

2、下载模型
进到Ollama官网,搜索deepsee-r1:https://ollama.com/library/deepseek-r1
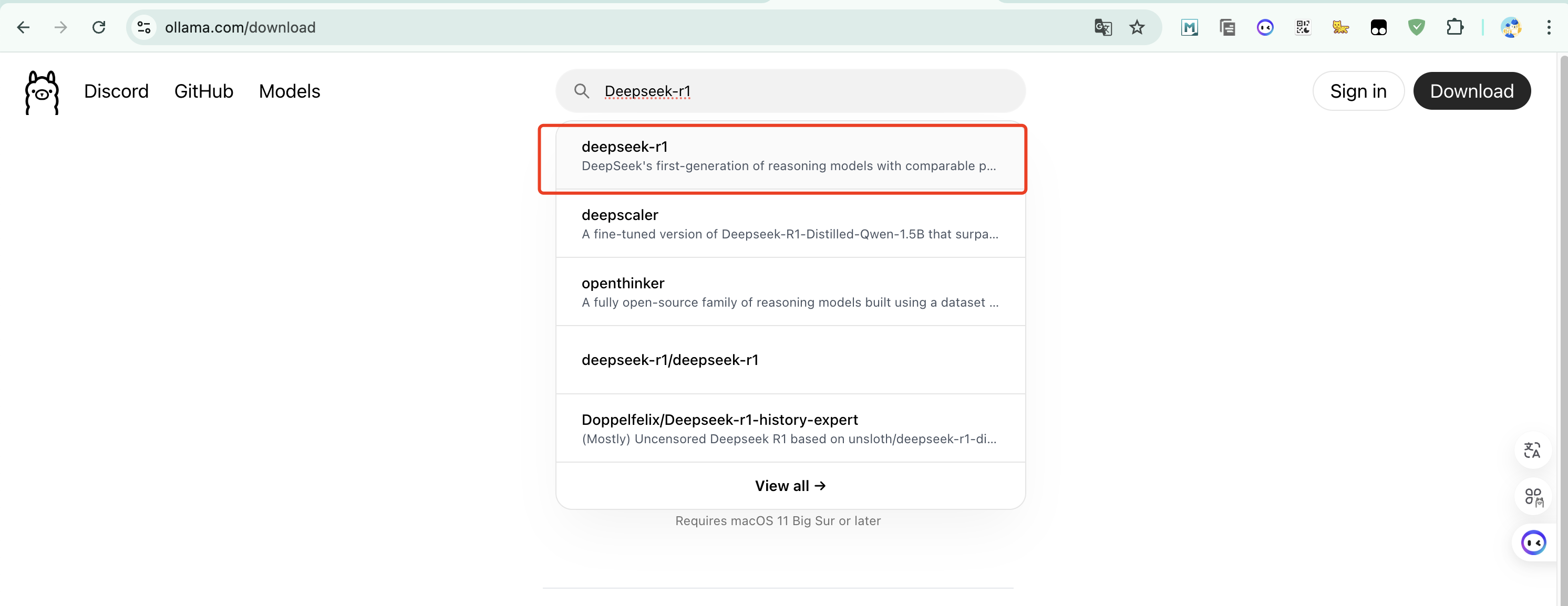
选择1.5b,其余的大家就别想了,具体原因可以看下我上面发的每个对应最低配置要求
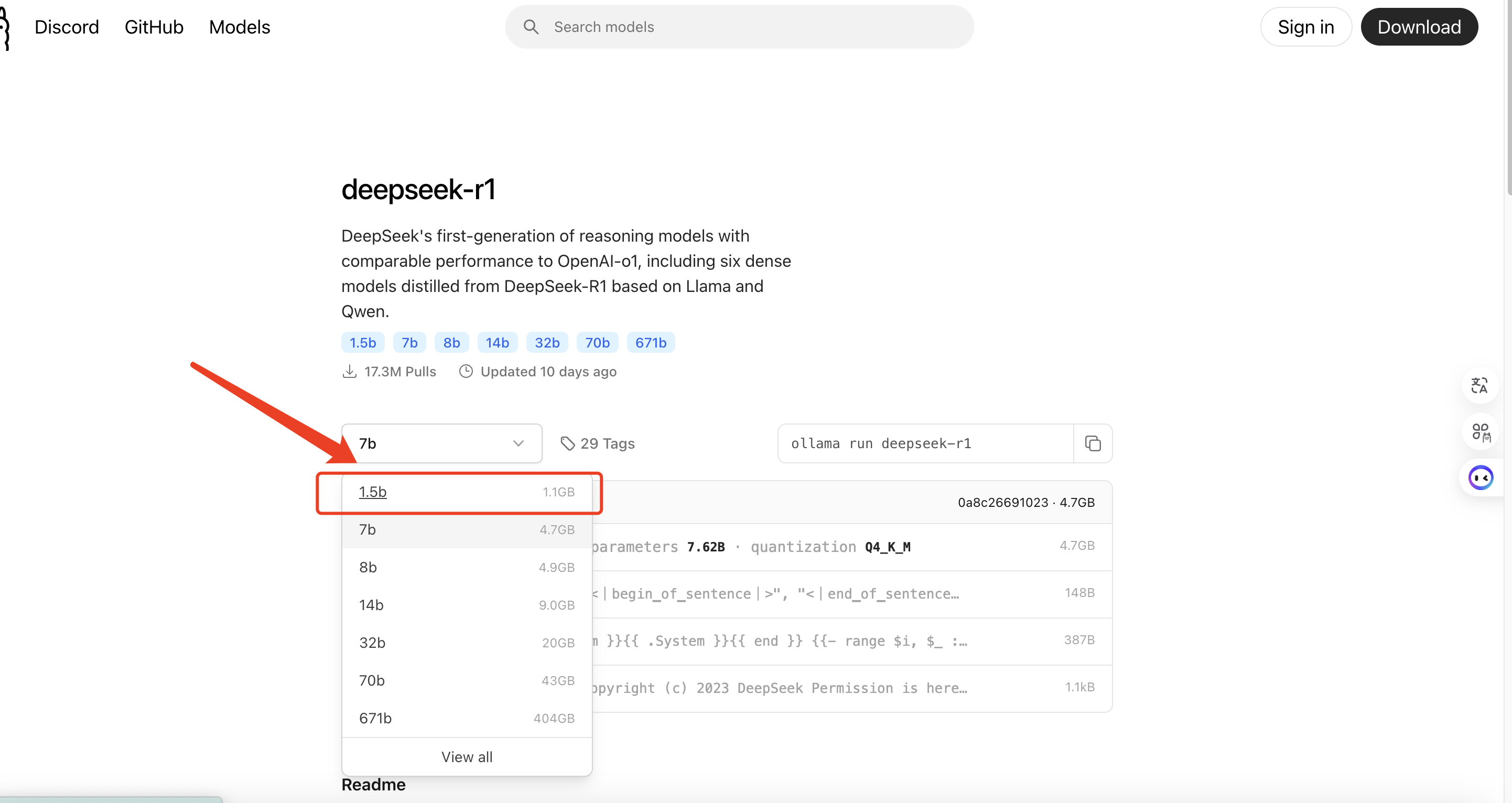
如果你的显卡足够强,也可以下载再高级一点的,具体参考如下
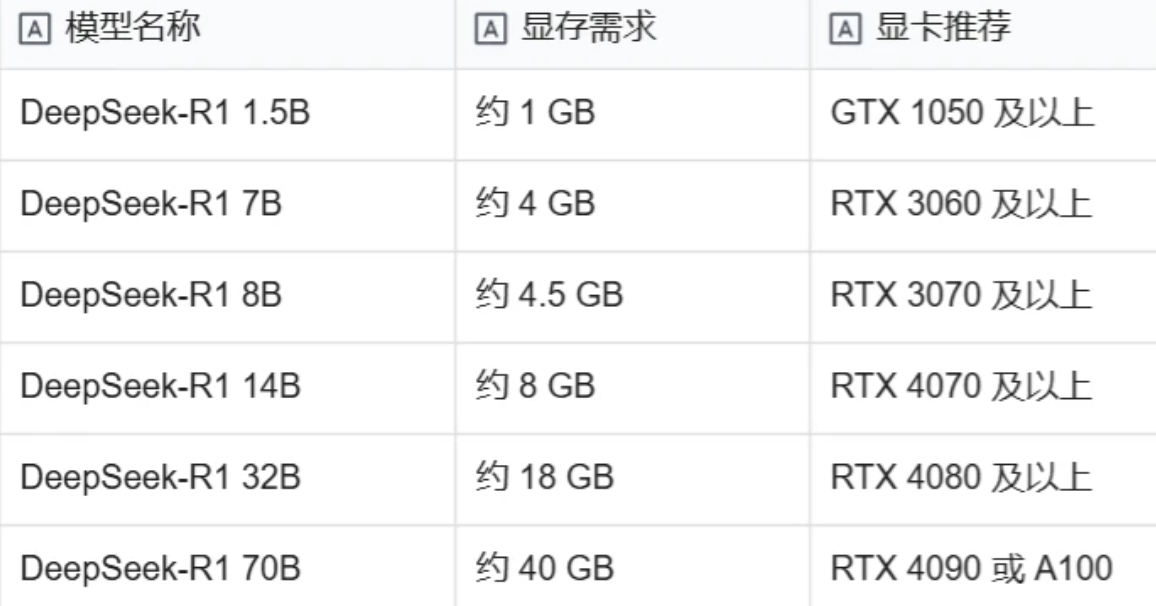
点击复制命令
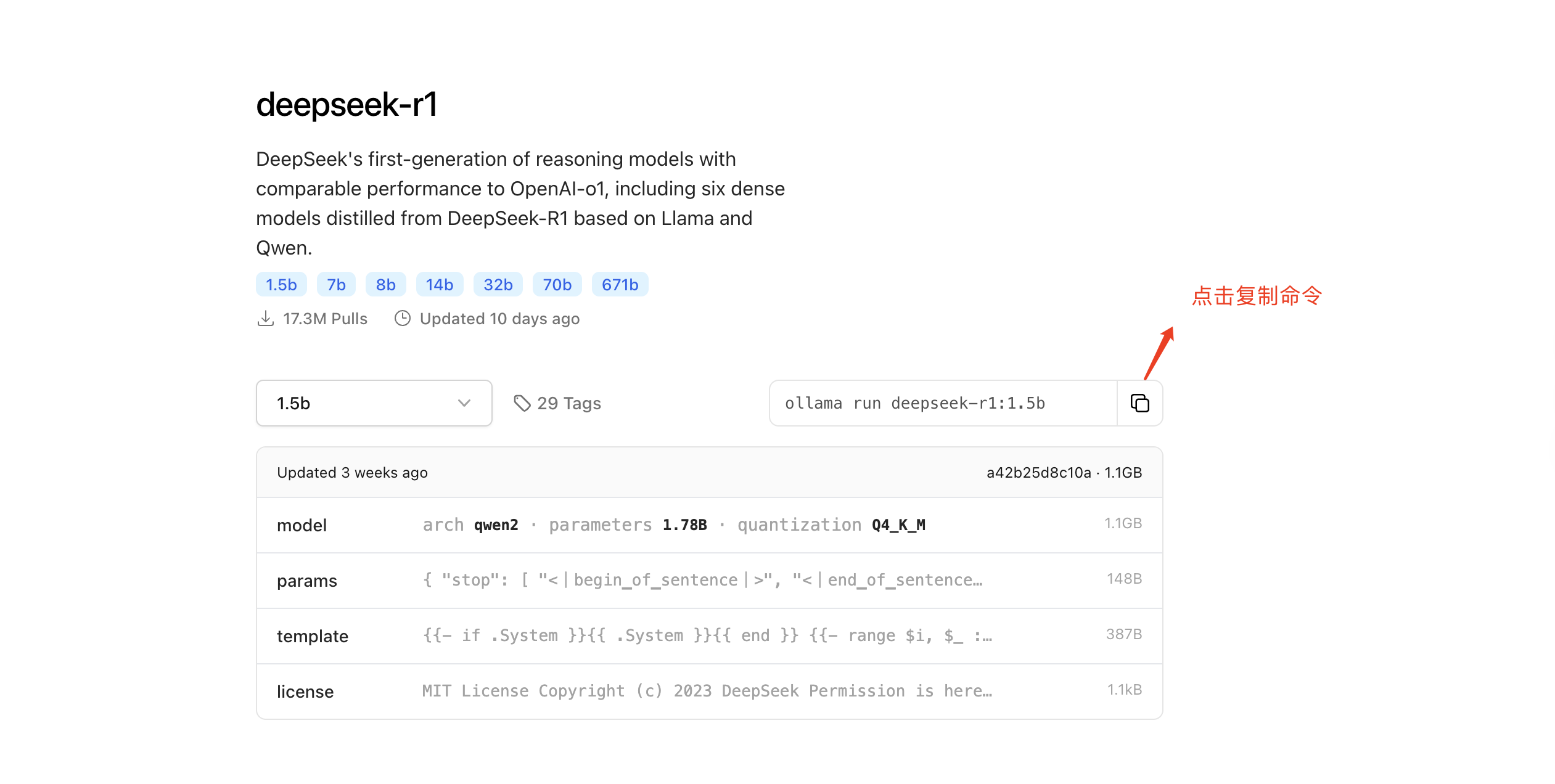
3、安装模型
直接使用上面复制的命令,在终端窗口输入即可开始安装,包1.1G,网速快的话一般5分钟左右就下载完成
1 | |
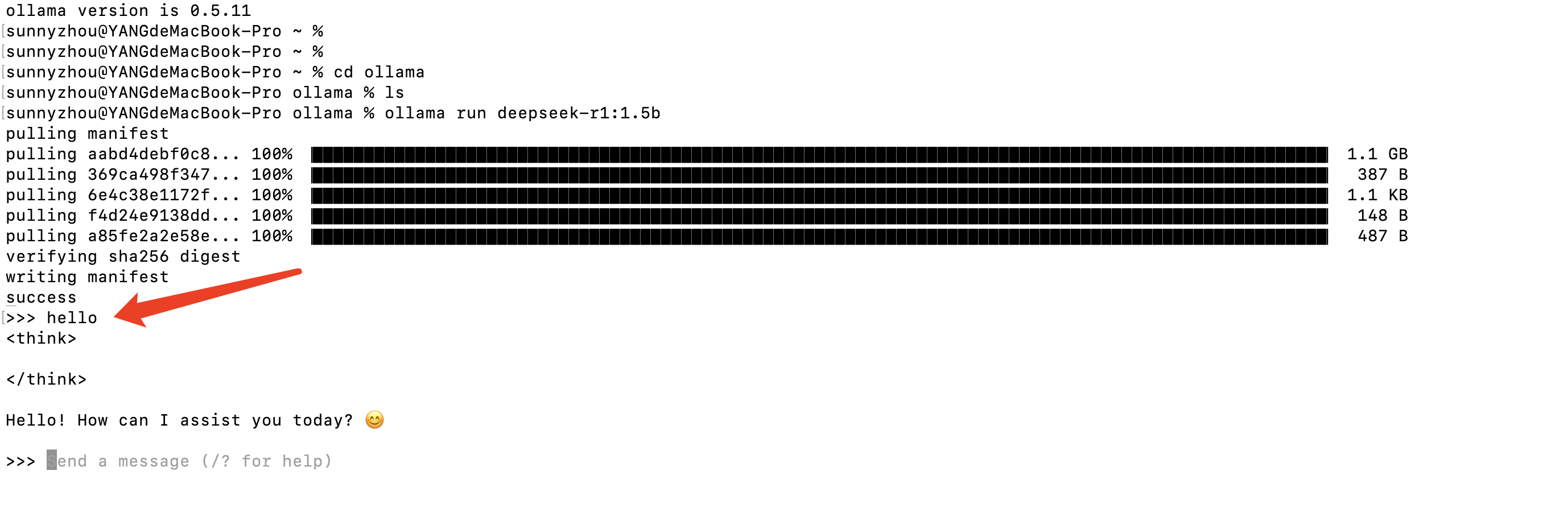
4、开始使用
上一步模型下载到本地后,就会自动进入到终端对话窗,开始对话使用了!
使用以下命令可以看到相关操作项
1 | |
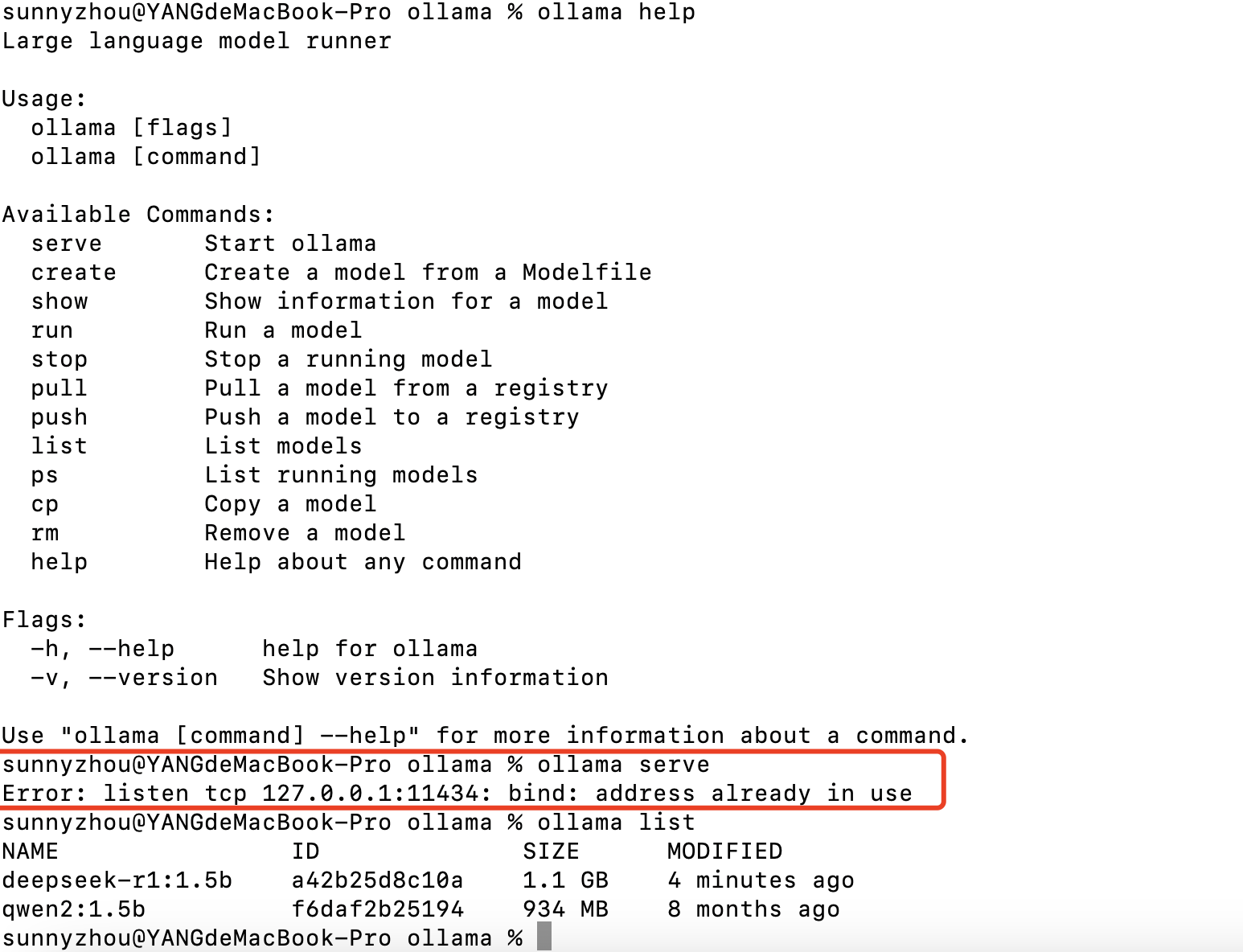
如何在本地可视化UI界面使用?
下载个Chatbox,该聊天工具可以直接引入Ollama API
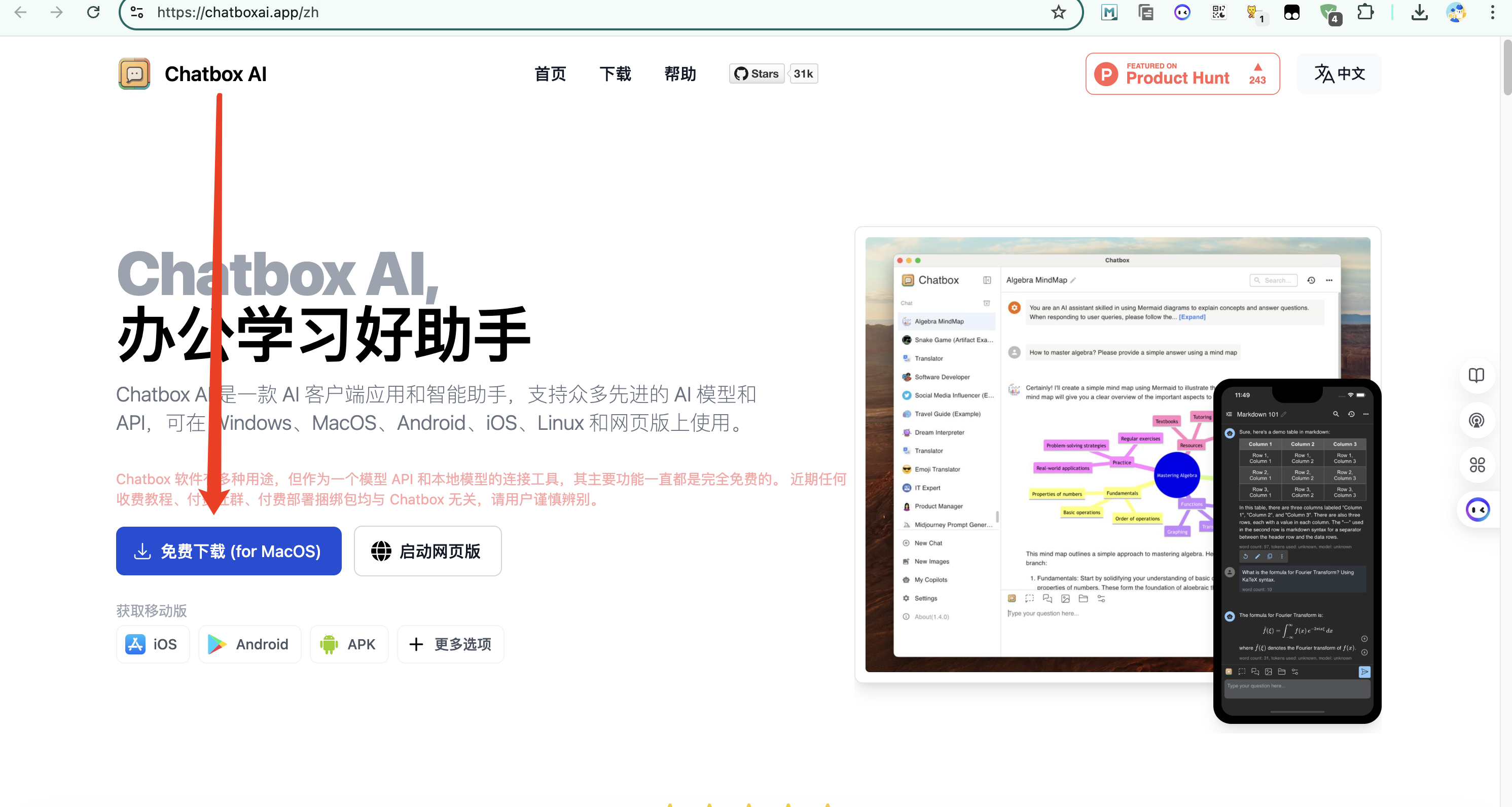
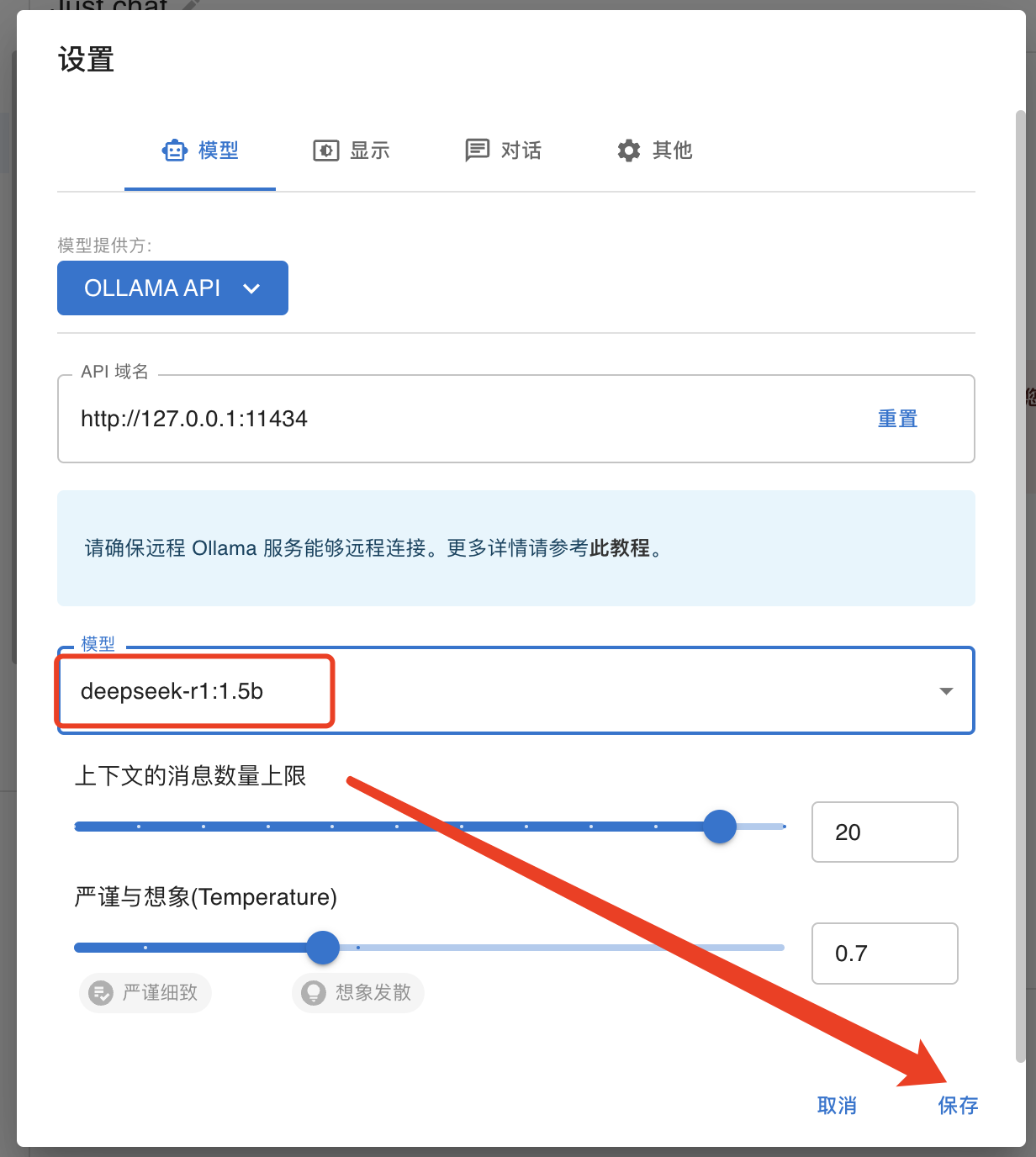
打开安装包后,界面如下,选择自己的API Key
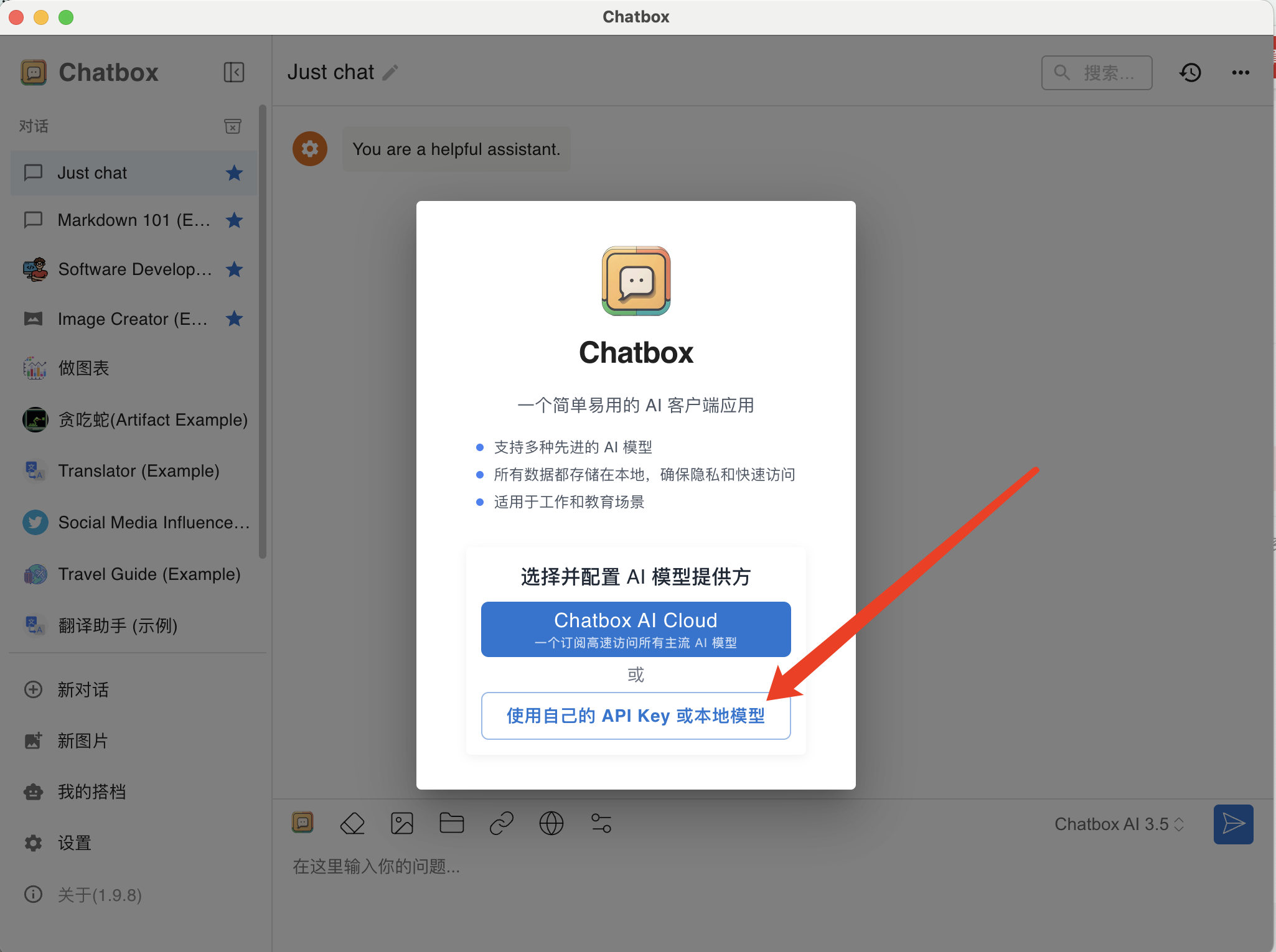
这里我们选择Ollama API
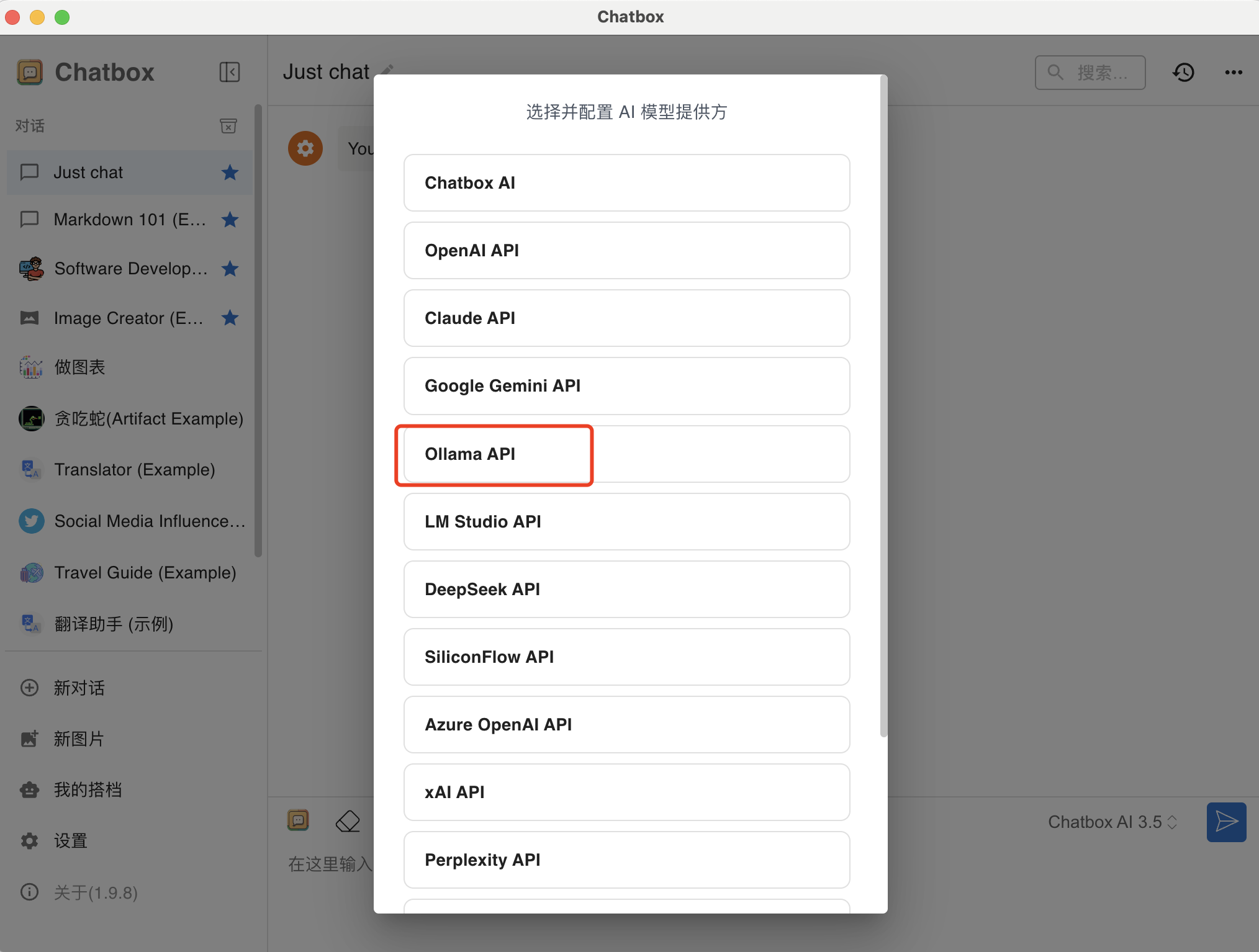
这里会自动识别本地的ollama地址,选择好模型直接保存即可
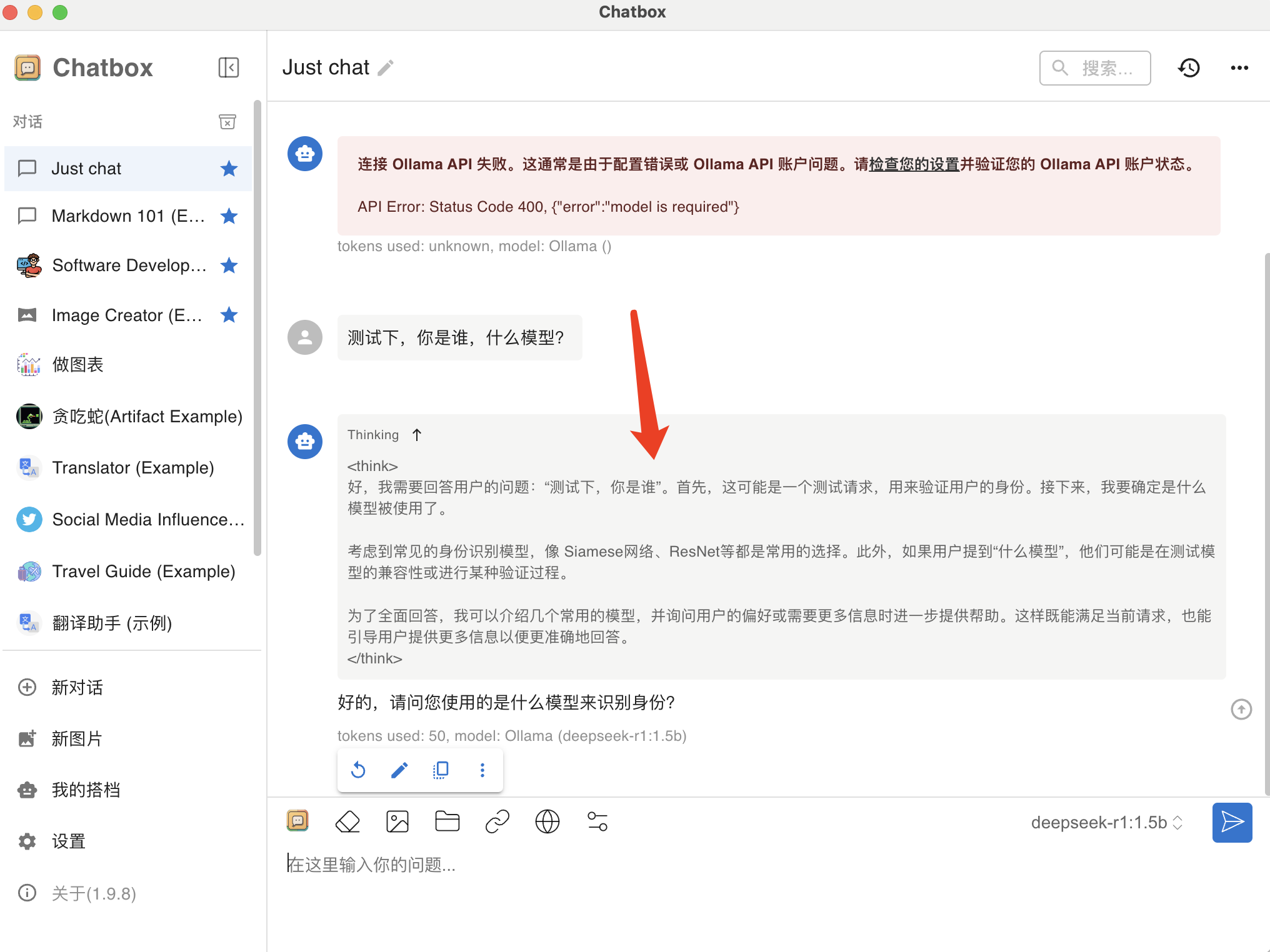
接下来,返回聊天界面测试下,推理模型正常用,完美!
总结
本篇文章详细讲解了DeepSeek的三种使用方式:总的来说,选择哪种方案取决于你的具体需求和预算。
**如果你需要高性能模型并且预算充足,云上部署或者企业内部部署是不错的选择**。如果你更关注隐私和稳定性,本地部署则是理想之选。而对于普通用户,第三方平台提供的网页和客户端服务可能是最便捷的。
无论选择哪种方式,提前做好准备总是明智的。希望这篇指南能帮助你顺利部署DeepSeek R1,充分利用这款强大的AI模型。如果你有其他好的建议或者经验,欢迎在评论区分享。让我们一起探索AI技术的无限可能。