性能评分超越DeepSeek R1?阿里QWQ-Max它来了!
就在上周,DeepSeek一口气新增开源了五大核心技术:**FlashMLA、DeepEP、DeepGEMM、DualPipe、3FS**,今天带大家一文看懂这些新开源的技术都是什么?以及普通人如何利用这些新开源技术!
FlashMLA:让NLP推理飞起来!
FlashMLA 是 DeepSeek 为 NVIDIA Hopper 架构 GPU 量身打造的高效 MLA(多头线性注意力)解码内核,专为处理变长序列而生!通过优化 KV 缓存机制和采用 BF16 数据格式,FlashMLA 在 H800 SXM5 GPU 上实现了惊人的 3000 GB/s 内存带宽和 580 TFLOPS 计算性能。无论是大语言模型(LLM)推理,还是自然语言处理(NLP)任务,FlashMLA 都能让你轻松应对!
主要亮点:
- BF16 精度支持:性能与效率的完美平衡。
- 页式 KV 缓存:64 块大小,内存管理更精细。
- 极致性能:3000 GB/s 带宽 + 580 TFLOPS 算力,AI 推理快到飞起!
适用场景:
- 机器翻译、文本生成、情感分析等 NLP 任务。
- 大语言模型推理,实时交互应用(如对话 AI、实时翻译)。
- 金融、医疗、教育等行业的高性能计算需求。
如何使用?
1、GitHub 下载工程
地址:https://github.com/deepseek-ai/FlashMLA
2、环境准备
FlashMLA 需要以下硬件和软件环境:
- 硬件:NVIDIA Hopper 架构 GPU(例如 H800 SXM5)。
- 软件:CUDA 12.3 及以上版本;PyTorch 2.0 及以上版本。
3、安装FlashMLA
通过以下命令安装 FlashMLA:
1 | |
4、运行基准测试
安装完成后,可以通过运行以下命令进行性能测试:(此脚本将验证 FlashMLA 在当前环境下的性能表现,例如在 H800 SXM5 GPU 上,内存受限配置下可达到 3000 GB/s 的带宽,计算受限配置下可达到 580 TFLOPS 的算力。)
1 | |
5、使用 FlashMLA
以下是 FlashMLA 的典型使用代码示例:
1 | |
6、更多说明
完整代码和文档可访问 GitHub 仓库查看。
DeepEP:混合专家模型的通信加速器!
DeepEP 是 DeepSeek 开源的专家并行(EP)通信库,专为混合专家模型(MoE)训练和推理设计。通过高吞吐量、低延迟的全对全 GPU 内核,DeepEP 支持 FP8 数据格式调度,延迟低至 163 微秒!无论是节点内 NVLink 还是跨节点 RDMA 通信,DeepEP 都能轻松搞定。
主要亮点:
- 高效通信内核:全对全 GPU 内核,吞吐量爆表!
- 低延迟推理:延迟低至 163 微秒,推理解码快到没朋友。
- 通信与计算重叠:基于 Hook 的设计,最大化计算效率。
适用场景:
- 大规模模型训练、推理任务。
- 智能客服、金融风险评估等高性能计算场景。
如何使用?
1、GitHub 下载工程
地址:https://github.com/deepseek-ai/DeepEP
2、使用DeepEP训练模型
具体训练放肆可在github参考代码示例
DeepGEMM:FP8 矩阵乘法的终极武器!
DeepGEMM 是 DeepSeek 开源的 FP8 矩阵乘法库,专为 NVIDIA Hopper 架构优化。通过即时编译(JIT)技术和细粒度缩放,DeepGEMM 在多种矩阵形状下性能爆表,最高加速比达 2.7 倍!无论是普通 GEMM 还是 MoE 分组 GEMM,DeepGEMM 都能轻松应对。
主要亮点:
- 高效 FP8 计算:细粒度缩放 + 双级累加,精度与性能兼得。
- 即时编译(JIT):运行时动态优化,无需安装时编译。
- 轻量级设计:核心代码仅 300 行,学习优化超简单!
适用场景:
- 大规模 AI 模型推理、混合专家模型(MoE)训练。
- 低精度计算、高性能计算任务。
如何使用?
1、下载工程
地址:https://github.com/deepseek-ai/DeepGEMM
2、安装deep_gemm
1 | |
3、性能表现
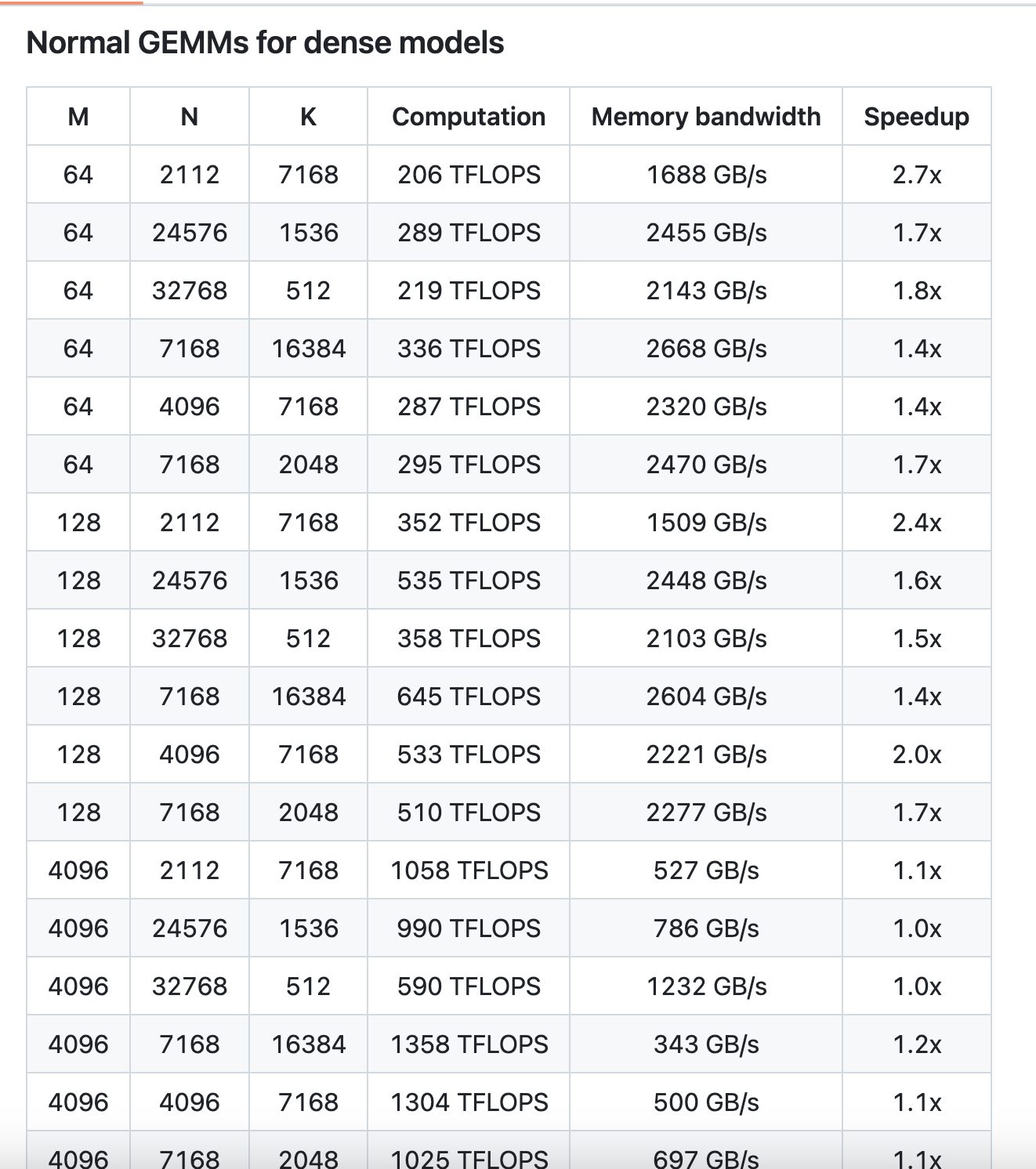
- 普通GEMM(非分组)性能
- 最高加速比:在某些矩阵形状下,DeepGEMM能达到2.7倍的加速比,显著提升矩阵乘法的效率。
- 计算性能:在大规模矩阵运算中,DeepGEMM能够实现超过1000 TFLOPS的计算性能,接近Hopper架构GPU的理论峰值。
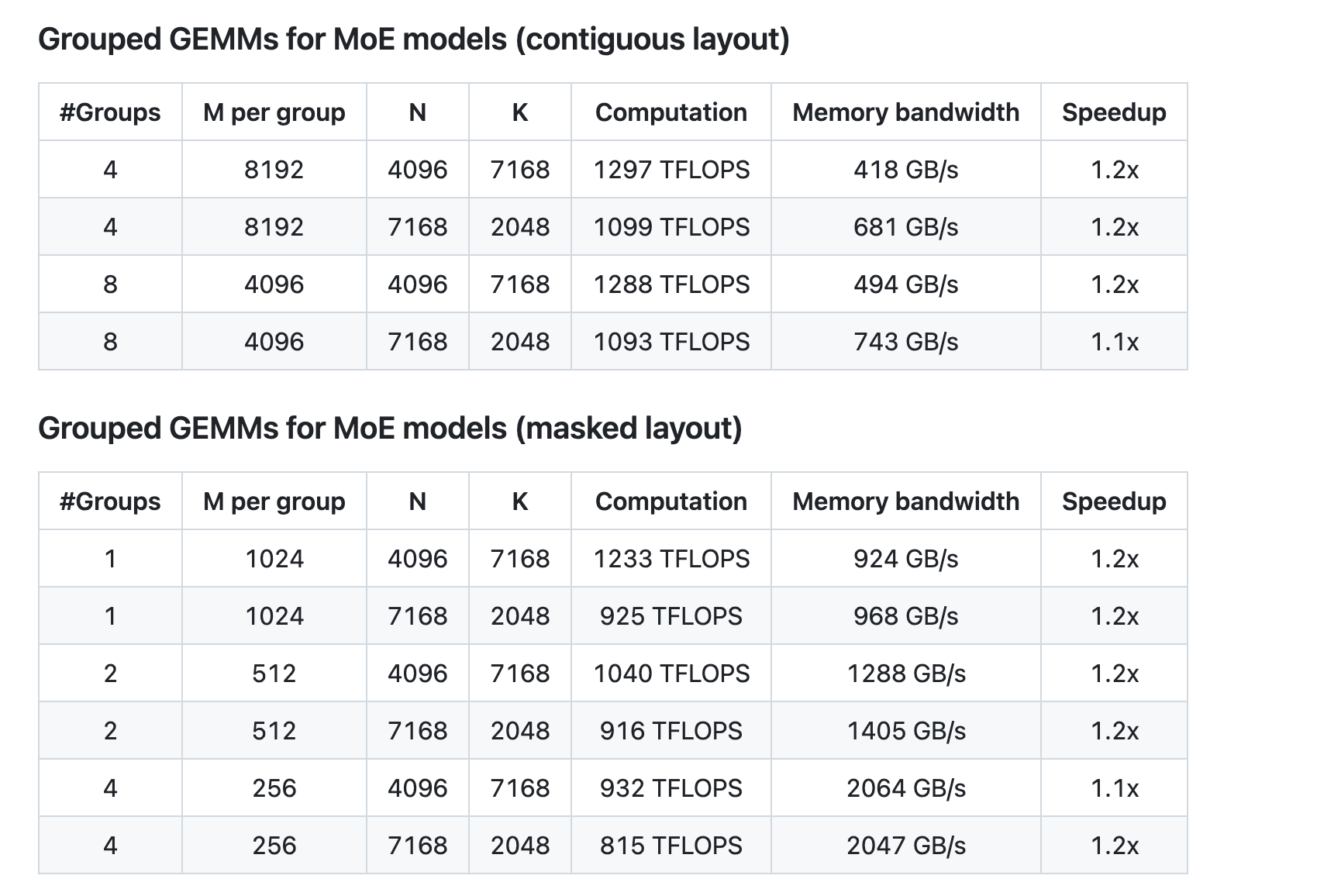
- 分组GEMM(MoE模型)性能
- 加速比:在分组GEMM中,DeepGEMM能实现1.1-1.2倍的加速比,显著提升MoE模型的训练和推理效率。
- 内存带宽优化:基于TMA特性,DeepGEMM在内存带宽利用上表现出色,达到接近硬件极限的性能。
- 连续布局(Contiguous Layout)
- 掩码布局(Masked Layout)
DualPipe:双向流水线并行,训练速度翻倍!
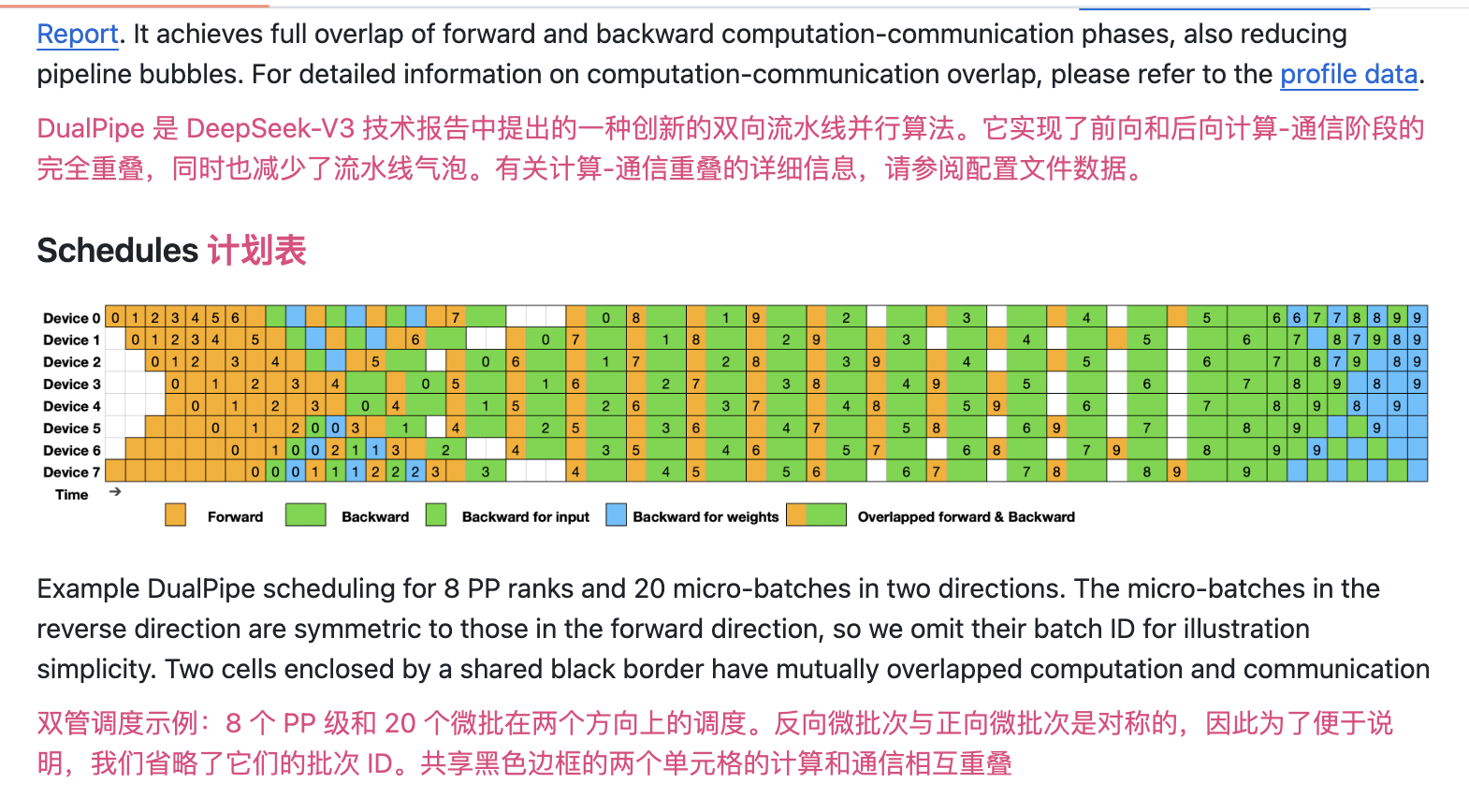
DualPipe 是 DeepSeek 开源的创新双向流水线并行技术,专为大规模深度学习模型训练设计。通过将前向计算和反向计算解耦为两个独立管道,DualPipe 实现了计算与通信的完全重叠,大幅提升训练效率!
主要亮点:
- 双向流水线设计:前向与反向计算并行执行,资源利用率最大化。
- 降低内存峰值:错峰执行,硬件资源需求更低。
- 训练速度翻倍:流水线式处理,模型迭代更快!
适用场景:
- 大规模模型训练、推理加速。
- 多模态数据处理、多任务学习。
如何使用?
1、下载工程
地址:https://github.com/deepseek-ai/DualPipe
2、启动示例工程
1 | |
这里配置有点专业,具体可以参考其配置文件
3FS:高性能分布式文件系统,AI 训练的神助攻!
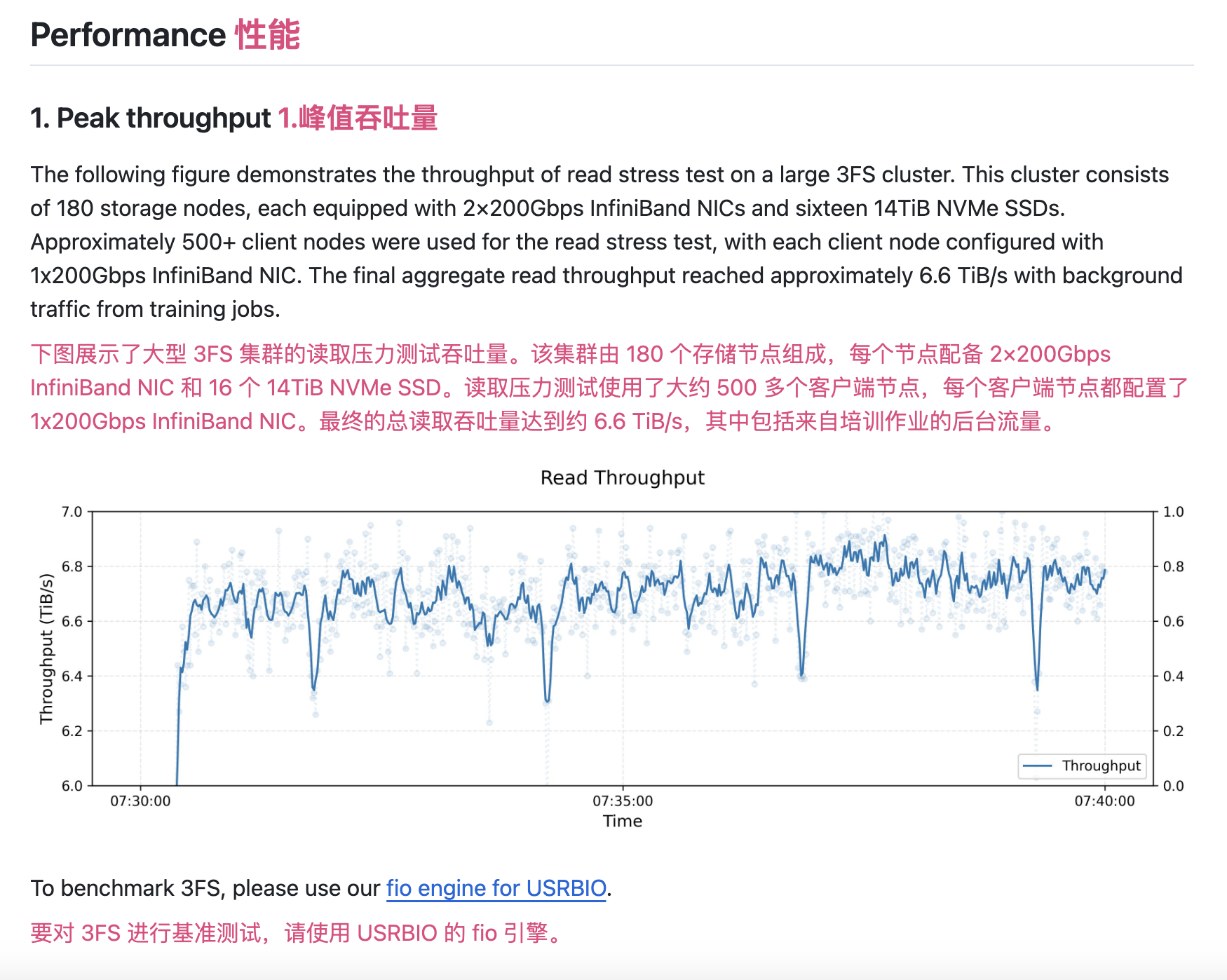
3FS 是 DeepSeek 开源的高性能分布式文件系统,专为 AI 训练和推理任务设计。通过聚合数千个 SSD 的吞吐量和数百个存储节点的网络带宽,3FS 提供高达 6.6 TiB/s 的读取吞吐量,强一致性保障让数据管理更轻松!
主要亮点:
- 高性能数据访问:6.6 TiB/s 读取吞吐量,AI 训练快到飞起!
- 强一致性保障:链式复制与分配查询(CRAQ)技术,数据安全无忧。
- KVCache 优化:推理任务缓存替代方案,效率提升显著。
适用场景:
- 大规模 AI 训练、分布式数据处理。
- 推理优化、检查点支持。
如何使用
1、下载工程
下载地址:https://github.com/deepseek-ai/3FS
1 | |
2、检查子模块
当 <font style="color:rgba(222, 18, 99, 0.835);">deepseek-ai/3fs</font> 克隆到本地文件系统后,运行以下命令检查子模块:
1 | |
3、安装依赖项
1 | |
4、Build 3FS
<font style="color:rgba(222, 18, 99, 0.835);">build</font> 文件夹中的 Build 3FS:
1 | |
5、运行集群测试
按照设置指南运行测试集群,以下是峰值吞吐量
总结
今天分享的这篇文章有点专业,主要针对AI大模型有深入了解的人员使用,总结起来就两个字:牛逼!
目前DeepSeek官网对话及API调用均表现速度有点慢,继续推荐个字节旗下火山引擎的DeepSeek-API(https://volcengine.com/L/LVGI8nt54yY/),不仅可以网页免费体验DeepSeek-R1联网模型,每日还免费赠送50万tokens(**基本上用不完**)!
**注意:使用邀请码:K1449QIJ**,每日获取的tokens额度会翻倍!!!直接自己注册登录就只能拿普通的tokens数了!
