EasyOCR – 支持超80种语言的开源OCR项目
大家在做日常开发时,想必一定开发过OCR识别需求,例如:身份证号识别、银行卡号识别、菜单识别,大部分项目都是通过调用其余公司开放平台的API接口实现的,而且基本上只支持识别:中文、数字、英文,而且每次调用都要收取调用费用!
今天,手把手带大家部署一款开源ocr项目,不仅支持80多种语言和多种书写系统,包括中文、阿拉伯文和西里尔文。而且它还基于深度学习技术,提供了高精度的文字识别能力。这款开源工具便是EasyOCR,目前github上已达26.1K Star

EasyOCR:多语言光学字符识别工具详解
EasyOCR 是一个功能强大的开源OCR(光学字符识别)项目,支持80多种语言和多种书写系统,包括中文、阿拉伯文和西里尔文。
用户可以通过简单的API轻松地将图像中的文本转换为可编辑的文本。EasyOCR易于安装和使用,**支持跨平台操作,适用于批量处理图像文件**。对图像质量有一定要求,在处理大型图像时速度较慢,不过还是一个用户友好的OCR工具。
一. 核心功能与能力
多语言支持:EasyOCR能够识别80多种语言和所有流行的书写系统,包括拉丁文、中文、阿拉伯文、梵文、西里尔文等。
高精度识别:依托深度学习技术,EasyOCR可以准确识别各种字体、字号和印刷质量的文本。
简单易用:提供简洁的API,使得开发者可以轻松集成和使用OCR功能。
跨平台兼容性:EasyOCR可以在Windows、macOS和Linux等操作系统上运行,不受限于特定的平台。
批量处理能力:支持同时处理多个图像文件,提高了处理大量图像的效率。
实时性能:默认使用纯内存运算,以提高处理速度和响应时间。
自定义训练:允许用户根据自己的需求训练模型,提高识别准确率。
图像预处理:提供图像清理功能,可以对图像进行去噪、二值化、旋转校正等预处理操作,以提高识别精度。
二. 用户体验与界面,如何操作
目前有两种方式,如果只是想体验效果可以进体验版,要自己部署可以按方法二根据源码安装
1、使用web版体验
体验版地址:https://www.jaided.ai/easyocr/
打开web版界面如下,选择需要识别的图片文件
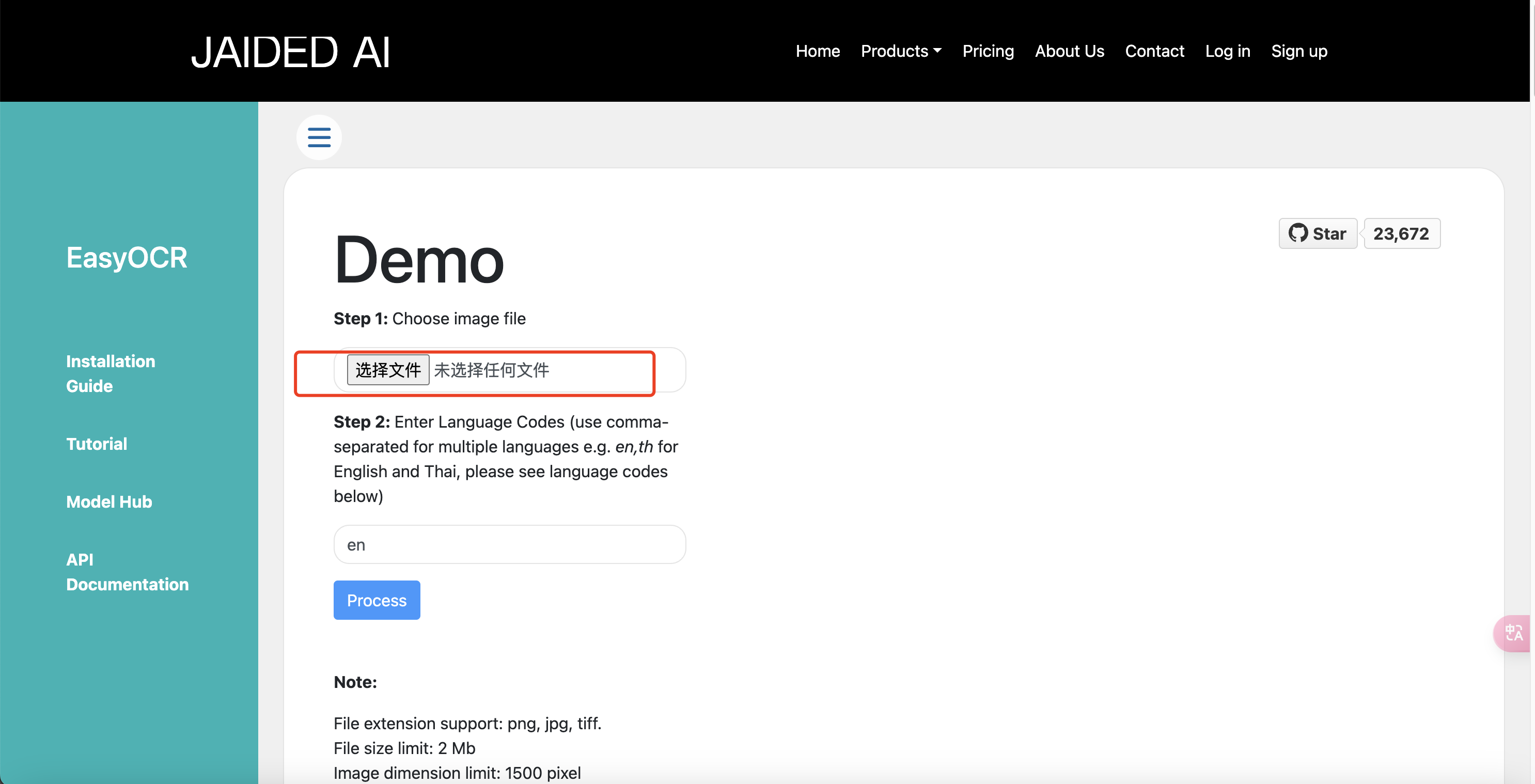
这里我们上传张身份证测试下

识别语言输入:ch_sim,这个对应的是简体中文,需要其余的可以参考语言映射表

点击process,一般几秒内便可识别完成,识别结果如下,可以看的出还是很精准的!

2、根据源码安装
源码地址:https://github.com/JaidedAI/EasyOCR
easyOCR支持pip命令快速安装
安装与设置:EasyOCR的安装非常简单,只需使用pip命令即可完成:
安装release版本
1 | |
如果想使用最新代码可以用源码安装
1 | |
模型默认存储路径
windows: C:\Users\username.EasyOCR</font>
linux:/root/.EasyOCR/
导入与使用:在Python脚本中导入EasyOCR库,创建Reader对象并指定语言,然后读取图像进行文本识别:
代码实现如下:
1 | |
结果处理:识别结果是一个包含文本和位置信息的列表,可以根据需求进行处理和展示。
easyocr 的深度学习算法依赖于另一个著名的第三方模块 pytorch,图形处理部分则会用到 opencv、Pillow 等,所以还需要确保自己电脑上已经安装这些基础模块。
首次使用easyocr识别图片,会自动从网络中下载预训练模型。
如果下载很慢,可以直接下载模型文件:https://www.jaided.ai/easyocr/modelhub/,下载完成后不用解压直接复制粘贴于~/.EasyOCR/model/目录下。

三. 涉及到的技术有哪些
深度学习模型:EasyOCR使用深度学习算法,特别是卷积神经网络(CNN),来识别图像中的文字。
预训练模型:模型已经在大量的文本数据上进行了训练,能识别多种语言和字体。
字符分割:在识别过程中,EasyOCR需要将图像中的文本区域分割成单个字符或单词。
特征提取:通过提取图像中的关键特征(如形状、边缘、纹理)来识别文字。
序列模型:由于文本是序列数据,EasyOCR还会使用序列模型(如RNN或LSTM)来处理字符序列,以提高识别的准确性。
四. 使用场景与目标用户
文档数字化:将纸质文档转换为电子文档,便于存储和检索。
票据识别:自动识别发票、收据、账单和其他财务相关文档上的信息。
身份验证:用于读取和验证护照、身份证或驾驶执照上的信息。
物流跟踪:自动识别包裹上的条形码和地址信息,提高分拣和配送效率。
医疗记录管理:读取和数字化医生的手写处方、病历记录和其他医疗文档。
交通监控:识别车牌号码,以便于交通管理和执法。
五. 定价与订阅模式
EasyOCR是开源项目,免费提供给所有用户使用。用户可以通过GitHub访问项目源码,并根据需要进行修改和定制。
六. 社区与支持
EasyOCR拥有活跃的社区,用户可以通过GitHub提交问题、报告bug或贡献代码。此外,官方文档和示例代码也为用户提供了丰富的资源。
七. 未来发展
EasyOCR团队计划继续优化识别算法,提高处理速度和识别准确率。未来可能会增加更多语言支持和功能,进一步提升用户体验。
总结
EasyOCR是一款功能强大且易于使用的OCR工具,支持多种语言和书写系统。无论是文档数字化、票据识别还是身份验证,EasyOCR都能提供高效、准确的解决方案。
通过简单的API和跨平台兼容性,EasyOCR为开发者和企业提供了极大的便利!