DeepSeek-R1-0528:小升级背后的大飞跃,代码与推理能力惊艳全球
5月28日晚,DeepSeek官方在用户群中静悄悄地发布了一则简短通知:DeepSeek R1模型已完成”小版本试升级”。

这个被称为”小版本”的更新,实际上带来了令人惊叹的能力提升,让国内外开发者和AI爱好者纷纷惊呼”这哪是小升级,简直是质的飞跃!”

本文将为您详细解析DeepSeek-R1-0528的升级内容、测试效果对比以及其在全球AI格局中的重要意义。
一、本次升级的核心内容:深度思考,更强推理
1. 深度思考能力显著增强
DeepSeek-R1-0528仍然使用2024年12月发布的DeepSeek V3 Base模型作为基座,但在后训练过程中投入了更多算力和引入算法优化机制,大幅提升了模型的思维深度与推理能力。
最直观的体现是思考深度的提升:**在AIME 2025数学测试集上,旧版模型平均每题使用12K tokens,而新版模型平均使用23K tokens,表明其在解题过程中进行了更为详尽和深入的思考**。这也直接反映在准确率上:AIME 2025测试中,准确率由70%提升至87.5%。

2. 幻觉问题大幅改善
新版DeepSeek R1针对”幻觉”问题进行了优化。与旧版相比,在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了45~50%左右,能够提供更为准确、可靠的结果。
3. 工具调用能力增强
DeepSeek-R1-0528首次支持工具调用(Function Calling),虽然暂不支持在thinking中进行工具调用。在Tau-Bench测评中,成绩为airline 53.5% / retail 63.9%,与OpenAI o1-high相当。

4. 前端代码生成能力大幅提升
新版模型在前端代码生成方面的改进尤为明显,不仅代码质量更高,默认审美也有大幅提升,能够生成更加美观、功能完善的前端页面。

5. 其他能力更新
- 创意写作:能够输出篇幅更长、结构内容更完整的长篇作品,呈现更加贴近人类偏好的写作风格
- 代码能力:在LiveCodeBench(2408-2505)测试中,Pass@1从63.5%提升至73.3%
- 知识问答:在GPQA-Diamond测试中,Pass@1从71.5%提升至81.0%
二、升级前后测试效果对比
1. 基准测试性能对比
| 类别 | 基准测试 | DeepSeek R1 | DeepSeek R1-0528 | 提升幅度 |
|---|---|---|---|---|
| 通用能力 | GPQA-Diamond (Pass@1) | 71.5% | 81.0% | +9.5% |
| 通用能力 | Humanity’s Last Exam (Pass@1) | 8.5% | 17.7% | +9.2% |
| 代码 | LiveCodeBench (Pass@1) | 63.5% | 73.3% | +9.8% |
| 代码 | Codeforces-Div1 (Rating) | 1530 | 1930 | +400 |
| 代码 | Aider-Polyglot (Acc.) | 53.3% | 71.6% | +18.3% |
| 数学 | AIME 2024 (Pass@1) | 79.8% | 91.4% | +11.6% |
| 数学 | AIME 2025 (Pass@1) | 70.0% | 87.5% | +17.5% |
| 数学 | HMMT 2025 (Pass@1) | 41.7% | 79.4% | +37.7% |
这些数据显示,DeepSeek-R1-0528在各项基准测试中均有显著提升,尤其在复杂推理任务、代码生成和数学问题解决方面的进步最为明显。
2. 前端代码生成能力对比
以下是实际测试案例中前端代码生成能力的对比:
案例1:创建个人网站
旧版R1生成的网站界面较为简单,布局基础,配色方案单一。而新版R1-0528生成的网站具有现代化设计、合理的空间布局、精美的过渡动画以及响应式设计,审美水平大幅提升。

案例2:天气卡片测试
新版R1-0528在复杂动画效果方面表现尤为出色,能够生成栩栩如生的天气效果动画,包括雨滴落下、雪花飘落、风的流动等细节,且代码结构清晰,易于维护。
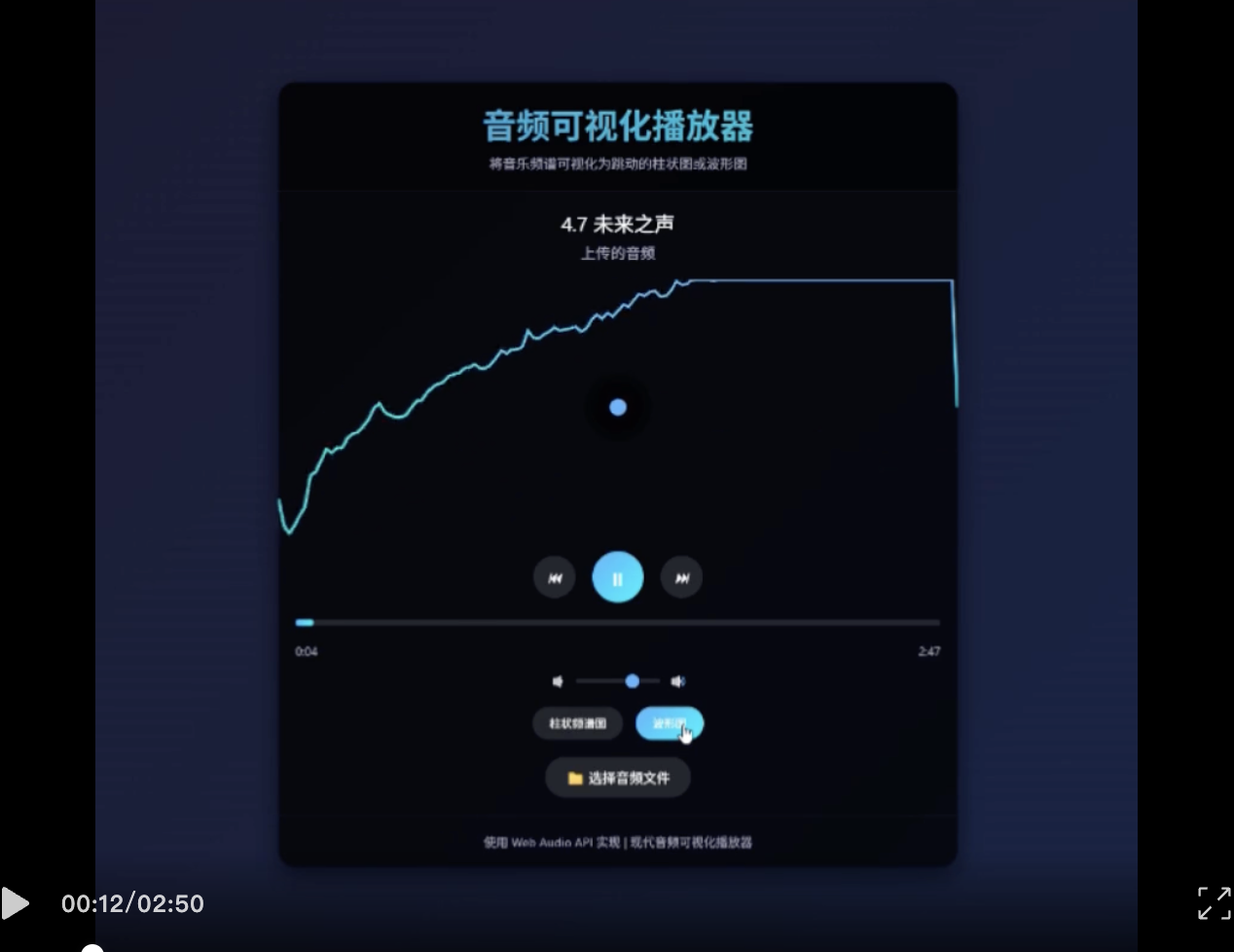
案例3:音频可视化播放器
新版R1-0528能够创建功能完整的音频可视化播放器,支持上传音乐、播放控制,并将音乐频谱可视化为跳动的柱状图或波形图,实现了复杂的音频处理和可视化功能。
3. 推理思考能力对比
在解决复杂数学问题时,新版R1-0528的思考过程更加深入和完整。以AIME竞赛题为例,新版模型会逐步分解问题,探索多种可能的解法,并在最终给出解答前详细验证结果的正确性。而旧版模型则可能在遇到困难时过早放弃,或得出不完整的解答。
三、全球AI格局中的定位与意义
1. 与全球顶尖模型的对比
根据独立评测机构Artificial Analysis的数据,DeepSeek-R1-0528在Intelligence Index(涵盖通用能力、数学、科学、代码等七项主流基准测试)中的得分从60跃升至68,这一提升幅度与OpenAI从o1到o3的提升相当。

综合智能水平已超过Anthropic的Claude4-Sonnet、阿里的Qwen3-235B、谷歌Gemini 2.5 Flash、xAI的Grok 3 mini(high)等推理模型,与谷歌Gemini 2.5 Pro持平,与OpenAI的o3和o4-mini(high)仅有两分之差,夺回全球最强开源模型的地位。
2. 开源与闭源的距离缩小
DeepSeek-R1-0528的突破表明,开源与闭源模型的差距正在缩小。这次更新不仅让DeepSeek成为与谷歌并列的全球第二AI实验室,还证明了开源模型可以与专有模型保持同等水平的智能提升。
更重要的是,DeepSeek-R1-0528依然保持开源,采用宽松的MIT License许可,支持商业使用和蒸馏,为开发者和研究人员提供了宝贵的资源。
3. 强化学习的价值凸显
DeepSeek在保持原有架构和预训练的情况下,通过强化学习技术实现了显著的智能提升。这表明,与预训练相比,扩大强化学习的规模可能是一种更高效的智能提升方式,尤其对计算资源较少的AI实验室具有重要参考价值。
四、总结与展望
DeepSeek-R1-0528虽被官方低调称为”小版本试升级”,但其实际带来的改进令人瞩目。它不仅在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,在全球范围内也已接近顶级闭源模型的水平。
这次升级的关键在于:
- 更深的思考深度:平均思考token数量增加近一倍
- 更强的推理能力:复杂推理任务准确率显著提升
- 更少的幻觉:幻觉率降低45-50%
- 更优的代码生成:尤其在前端代码生成方面表现突出
- 更完善的工具支持:新增Function Calling功能
DeepSeek-R1-0528的成功证明了后训练中强化学习的巨大潜力,也为开源AI社区注入了强大信心。随着DeepSeek持续专注于模型研发,我们有理由期待未来DeepSeek-R2的到来,将带来更加革命性的突破。
正如社区中流传的那句话:”这很DeepSeek,朴实无华、悄悄然地改变世界。”
注:本文内容基于公开资料整理,部分数据来源于DeepSeek官方发布的测评结果和社区用户的实测反馈。