2、探索和比较不同的LLM:如何在业务中选择最佳AI模型?
上篇文章我们分享了大模型的入门第一课程:LLM 的工作原理(https://mp.weixin.qq.com/s/nAmDextOH5m4T8sueqoy3w),今天继续分享下:探索和比较不同的 AI 模型,如何在不同的场景使用合适的模型!
分享前我们继续来回顾下本次所有要分享的内容:
课程总览(两大阶段,循序渐进)
第一阶段:生成式 AI 入门(1-21)

第二阶段:AI Agent 学习(设计模式到生产实践)

本章分享内容概览
内容核心包括:
- 当前技术生态中LLM的多元分类维度
- 利用Azure平台测试、优化并横向对比不同模型的实战方法
- 如何部署 LLM
学习目标
完成本章内容后,你将能够:
- 根据业务场景选择合适的 AI 大模型
- 理解如何测试、迭代并且提升模型的性能
- 了解企业如何部署模型
了解不同类型的LLM
LLM可以根据其架构、训练数据和应用场景进行多种分类。理解这些差异将帮助大家在拓展业务时,特别是初创企业,在具体的业务场景能够选择合适的模型,并掌握如何测试、迭代和提升性能。
LLM模型种类繁多,选择哪种模型取决于:使用目标、数据情况、预算等因素。
首先我们需要根据任务类型:如文本、音频、视频或图像生成,去选择不同的模型类型:
- 音频和语音识别。Whisper类模型是这类任务的理想选择,它们专注于通用语音识别,支持多语言识别。了解更多关于Whisper类模型。
- 图像生成。在图像生成领域,DALL-E和Midjourney是两个非常知名的选择。DALL-E由Azure OpenAI提供支持,后续的文章会和大家详细分享下它的设计模式。
- 文本生成。大多数模型都是做文本生成起家的,比如最早知名度最高的是:chatGpt,也可以选择 Claude、Gemini 等,国产模型关注度比较高的是:DeepSeek、Qwen、Kimi 等。它们的价格各异,GPT-4是最昂贵的。建议使用Azure OpenAI playground来评估哪些模型在能力和成本上最适合你的需求。
- 多模态。如果你需要处理多种类型的输入和输出数据,可以考虑像gpt-4 turbo带视觉功能或gpt-4o 这样的新OpenAI模型,它们能够结合自然语言处理和视觉理解,实现多模态交互。
选择模型后,你将具备一些基础能力,但这往往还不够。通常,还需要让 LLM 去学习自己公司独有的一些知识库数据。针对这一点,有几种不同的处理方式,后续章节会详细介绍。
基础模型与LLM的区别
“基础模型”一词由斯坦福研究人员提出,定义为满足以下条件的AI模型:
- 采用无监督学习或自监督学习训练,即在未标注的多模态数据上训练,无需人工注释或标注。
- 模型规模庞大,基于深度神经网络,拥有数十亿参数。
- 通常作为其他模型的“基础”,可作为构建其他模型的起点,通过微调实现特定任务。
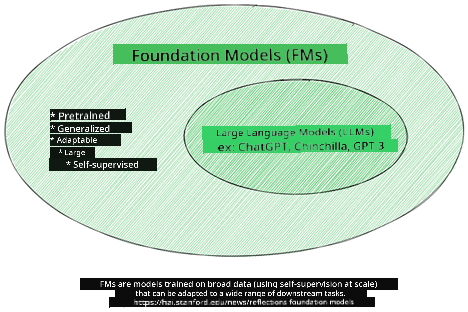
图片来源:Essential Guide to Foundation Models and Large Language Models | by Babar M Bhatti | Medium
为了进一步说明区别,我们以ChatGPT为例。ChatGPT的第一个版本基于GPT-3.5这一基础模型构建。OpenAI利用特定的聊天数据对GPT-3.5进行了微调,使其在对话场景(如聊天机器人)中表现出色。
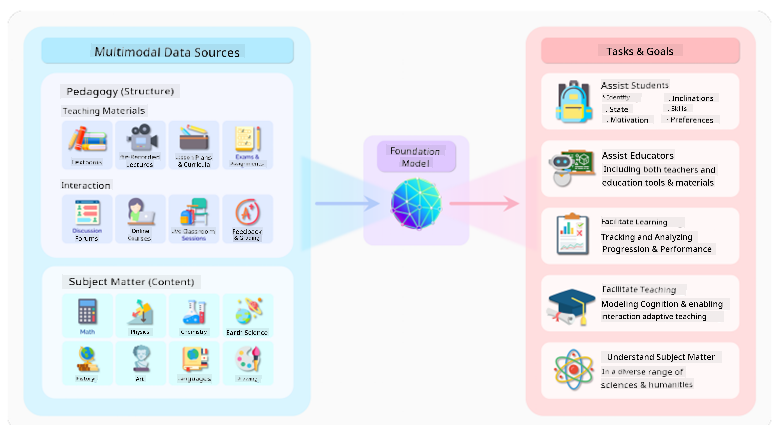
图片来源:2108.07258.pdf (arxiv.org)
开源模型与专有模型
另一种分类方式是根据模型是否开源。
开源模型是公开发布的,任何人都可以使用。它们通常由创建者公司或研究社区提供,允许用户查看、修改和定制以适应不同的LLM应用场景。但开源模型不一定针对生产环境进行优化,性能可能不及专有模型。此外,开源模型的资金支持有限,可能缺乏长期维护和最新研究的更新。流行的开源模型示例包括Alpaca、Bloom和LLaMA。
专有模型由公司拥有,不对外公开。这些模型通常针对生产环境进行了优化,但用户无法查看或修改它们。它们往往不是免费的,可能需要订阅或付费使用。用户必须信任模型所有者在数据隐私和AI责任使用方面的承诺。流行的专有模型示例包括OpenAI模型、Google Bard和Claude 2。
嵌入模型、图像生成模型与文本及代码生成模型
LLM还可以根据输出类型进行分类。
嵌入模型能够将文本转换为数值形式,称为嵌入,作为文本的数值表示。嵌入使机器更容易理解词语或句子之间的关系,并可作为其他模型(如分类或聚类模型)的输入。了解更多关于嵌入模型。

图像生成模型用于生成图像,常用于图像编辑、合成和转换。它们通常在大型图像数据集(如LAION-5B)上训练。示例包括DALL-E-3和Stable Diffusion模型。

文本和代码生成模型用于生成文本或代码,常用于文本摘要、翻译和问答。文本生成模型通常在大型文本数据集(如BookCorpus)上训练。代码生成模型,如CodeParrot,通常在大型代码库上训练,可生成新代码或修复错误。

编码器-解码器架构与仅解码器架构
在谈论LLM的不同架构时,我们可以用一个比喻来说明。
假设您的经理让您为学生设计一个测验。您有两个同事:一个负责内容创作,另一个负责审核。
内容创作者类似于仅解码器模型,他们可以根据主题和已有内容写作课程。他们擅长生成引人入胜的内容,但不擅长理解主题和学习目标。仅解码器模型的例子有GPT系列模型,如GPT-3。
审核者类似于仅编码器模型,他们查看已写课程和答案,理解它们之间的关系和上下文,但不擅长生成内容。仅编码器模型的例子有BERT。
如果一个人既能创作又能审核测验,那就是编码器-解码器模型。示例包括BART和T5。
服务与模型的区别
现在,我们来谈谈服务和模型的区别。服务是云服务提供商提供的产品,通常包含模型、数据和其他组件。模型是服务的核心,通常是基础模型,如LLM。
服务通常针对生产环境进行了优化,通过图形界面操作更方便。但它们不一定免费,可能需要订阅或按使用量付费。用户使用服务提供商的资源,优化成本并轻松扩展。示例服务有Azure OpenAI Service,它采用按使用量付费的计费方式,并提供企业级安全和负责任的AI框架。
模型仅指神经网络本身,包括参数和权重。企业若想本地运行模型,需要购买设备、搭建架构,并购买许可或使用开源模型。像LLaMA这样的模型可供使用,但需要计算资源来运行。
如何在Azure上测试和迭代不同模型以评估性能
当团队探索了当前LLM生态并确定了一些候选模型后,下一步是用自己的数据和工作负载对它们进行测试。这是一个通过实验和测量不断迭代的过程。大多数模型(如OpenAI模型、Llama2等开源模型和Hugging Face transformers)都可以在Azure AI Studio的模型目录中找到。
Azure AI Studio是一个云平台,专为开发者设计,用于构建生成式AI应用并管理整个开发生命周期——从实验到评估——通过整合所有Azure AI服务到一个便捷的中心。Azure AI Studio中的模型目录使用户能够:
- 在目录中找到感兴趣的基础模型——无论是专有还是开源模型,可以通过任务、许可证或名称筛选。为了提升搜索效率,模型被组织成多个集合,如Azure OpenAI集合、Hugging Face集合等。
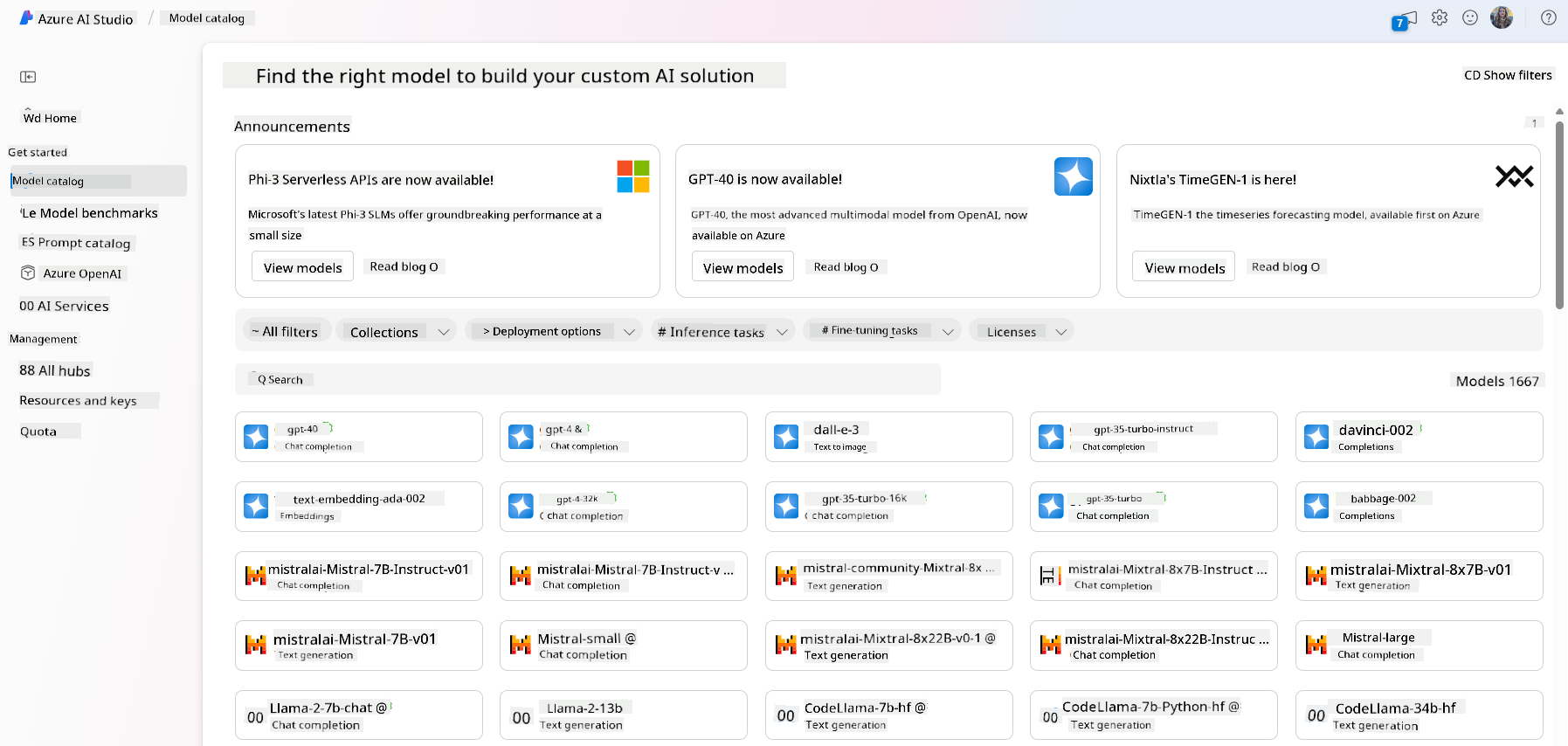
- 查看模型卡,包括详细的预期用途、训练数据、代码示例和评测结果。
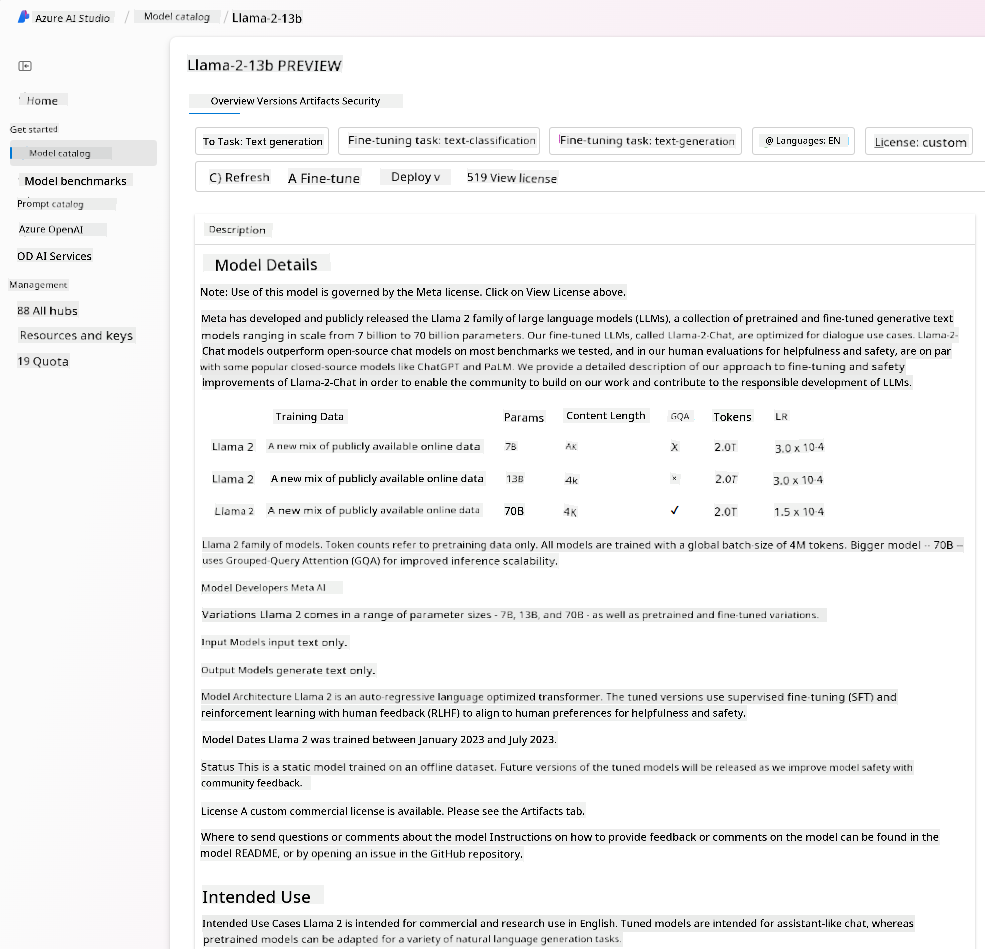
- 通过模型基准面板,比较不同模型在行业数据集上的表现,评估哪个模型更适合业务场景。
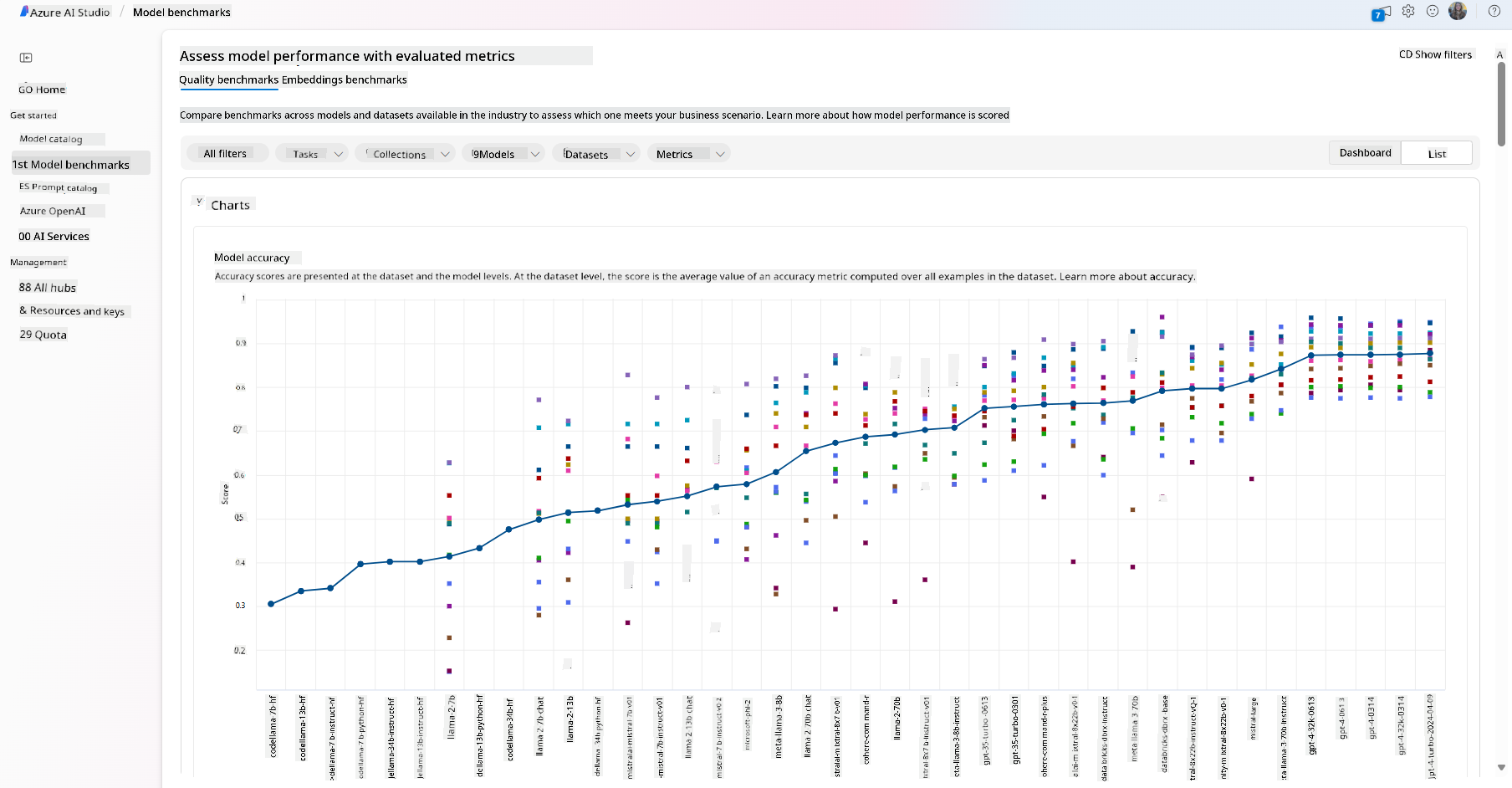
- 利用Azure AI Studio的实验功能,在自定义数据上微调模型,以提升特定工作负载下的表现。

- 将预训练模型或微调版本部署到托管计算或按需付费的无服务器API端点,以便应用程序调用。

提升大型语言模型(LLM)结果
前面内容已经讲解了不同类型的LLM,以及一个云平台(Azure Machine Learning),它使我们能够比较不同模型,在测试数据上评估它们,提升性能,并将其部署到推理端点。
那么,**什么时候应该考虑微调模型,而不是直接使用预训练模型?**是否有其他方法可以提升模型在特定工作负载上的表现?
企业可以采用多种方法来获得所需的LLM结果。部署LLM时,可以选择不同类型和训练程度的模型,权衡复杂度、成本和质量。以下是几种不同方式:
- **带上下文的提示工程**。核心思想是在提示时提供足够的上下文,确保获得所需的回答。
- **检索增强生成(RAG)**。例如,您的数据可能存储在数据库或网络端点中。为确保在提示时包含这些数据或其子集,可以检索相关数据并将其作为用户提示的一部分。
- **微调模型**。您在自己的数据上进一步训练模型,使其更精准和符合需求,但可能成本较高。
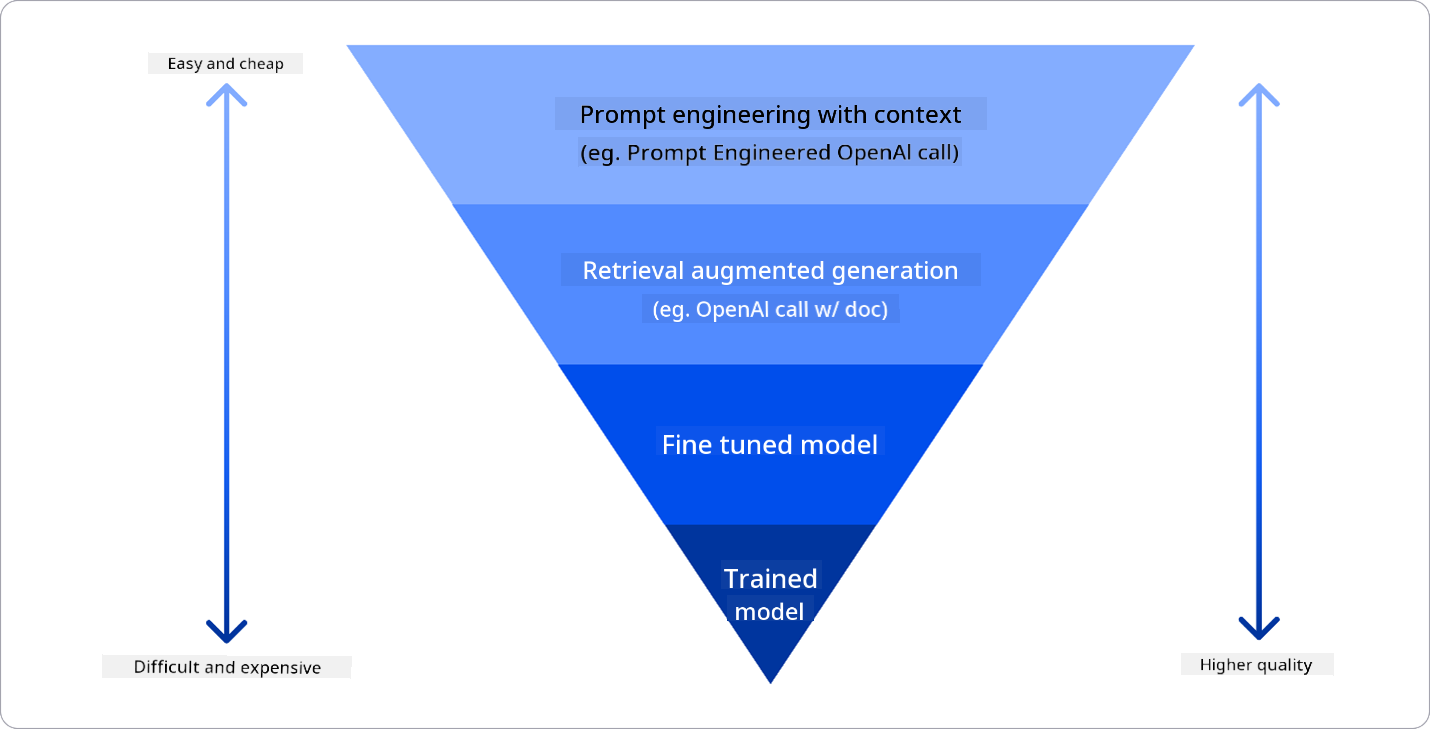
图片来源:Four Ways that Enterprises Deploy LLMs | Fiddler AI Blog
带上下文的提示工程
预训练的LLM在通用自然语言任务上表现良好,即使仅用简短提示调用,如完成句子或回答问题——这被称为“零样本”学习。
然而,用户越能详细构建查询并提供具体示例——即上下文——模型的回答就越准确。如果提示中只包含一个示例,称为“一样本”学习;包含多个示例则称为“少样本”学习。带上下文的提示工程是启动项目时最具成本效益的方法。
检索增强生成(RAG)
LLM的局限在于它们只能使用训练时所用的数据生成答案。这意味着它们不了解新数据或非公开信息(如公司内部数据)。RAG技术通过检索外部数据增强提示来解决这一问题(考虑提示长度限制)。该技术依赖向量数据库工具(如Azure Vector Search),从数据源中检索片段加入提示。
当企业缺乏足够数据或资源微调LLM,但仍希望提升性能并降低虚假信息风险时,这种技术非常有用。
微调模型
微调是利用迁移学习将模型“适配”到特定任务的过程。与RAG不同,微调生成新模型,更新权重和参数。它需要一组训练样本,每个样本包含输入提示和对应输出。适合情况包括:
- 使用低性能模型降低成本或提升速度。
- 高延迟要求导致提示长度受限。
- 企业拥有高质量数据并保持更新。
训练模型
从零开始训练LLM是最困难和复杂的方法,需要海量数据、专业人才和强大计算资源。只建议当企业有特定领域用例和大量数据时使用。
知识检测
那有什么方法可以提升LLM的结果呢?
- 带上下文的提示工程
- RAG
- 微调模型
答:3。如果您有时间、资源和高质量数据,微调是保持模型更新的更好选择。但如果想快速改进且时间有限,建议先考虑RAG,后面的文章会再详细讲解什么事 RAG,如何搭建数据库以及 AI 使用 RAG 代码实战!
视频教程
https://48673fs5cb16.vicp.fun/quanyouhulian/2、探索和比较不同的LLM.mp4
视频内容介绍:
- 当前布局中的不同类型的 LLM。
- 测试迭代和比较 Azure 中用例的不同模型。
- 如何部署和 LLM。
下节分享预告
第2课:如何负责任地构建生成式人工智能应用。