3、负责任地使用生成式 AI
上篇文章我们分享了探索和比较不同的LLM 以及如何在业务中选择最适合自己业务场景的 AI模型(https://mp.weixin.qq.com/s/1i3w4OG-PlH1xgQbD5Zi7A),今天继续分享:如何负责任的使用生成式 AI。
老规矩,分享前我们回顾下所有要分享的内容:
课程总览(两大阶段,循序渐进)
第一阶段:生成式 AI 入门(1-21)

第二阶段:AI Agent 学习(设计模式到生产实践)

生成式 AI 虽令人很强大,但需关注如何负责任地使用。你需要考虑输出公平性、无害性等核心问题。
本节内容包括:
- 为何构建生成式 AI 应用需要优先考虑负责任 AI
- 负责任 AI 核心原则与生成式 AI 的关联
- 如何通过策略工具践行这些原则
负责任 AI 原则
生成式 AI 正在经历前所未有的热度,吸引了大量开发者、资金的投入与关注。这对构建 AI 产品的团队来说是一个重大机遇,但更需负责任地推进。
负责任的使用 AI六大原则:
公平性 • 包容性 • 可靠性/安全性 • 隐私保护 • 透明度 • 问责制
在使用 AI 过程中,我们将探讨这些原则如何应用于产品。
为何优先考虑负责任 AI
采用以人为本的构建理念,始终将用户利益置于首位,才能创造最佳产品。
生成式 AI 的独特价值在于能够自动生成实用答案、信息指导和准备内容,其生成答案和效率非常惊人。但若缺乏规划与策略,AI 可能对用户、产品及社会造成伤害。
以下是典型风险案例:
▎幻觉问题(Hallucination)
指大型语言模型(LLM)生成完全错误或与事实严重不符的内容。
案例场景
某历史问答功能中,学生提问:”泰坦尼克号的唯一幸存者是谁?”
模型给出自信而详细的错误回答:
(来源:Flying bisons)

此类输出会损害系统可靠性,甚至影响企业声誉。尽管新版 LLM 已减少幻觉概率,但开发者仍需警惕该问题的出现。
▎有害内容
除错误信息外,LLM 可能生成:
- 煽动自残/群体伤害的内容
- 仇恨或贬损性言论
- 暴力行为指导
- 违法活动指引
- 色情信息
教育类产品尤其需要建立防护机制,防止学生接触此类内容。
▎公平性缺失
公平性要求”AI 系统无偏见地平等对待所有人群”。生成式 AI 需避免强化对边缘群体的排斥性世界观,否则不仅破坏用户体验,更会造成社会伤害。开发者应始终考虑用户多样性,构建包容性解决方案。
四步实践负责任生成式 AI
识别风险后,可通过四个层次构建防护体系: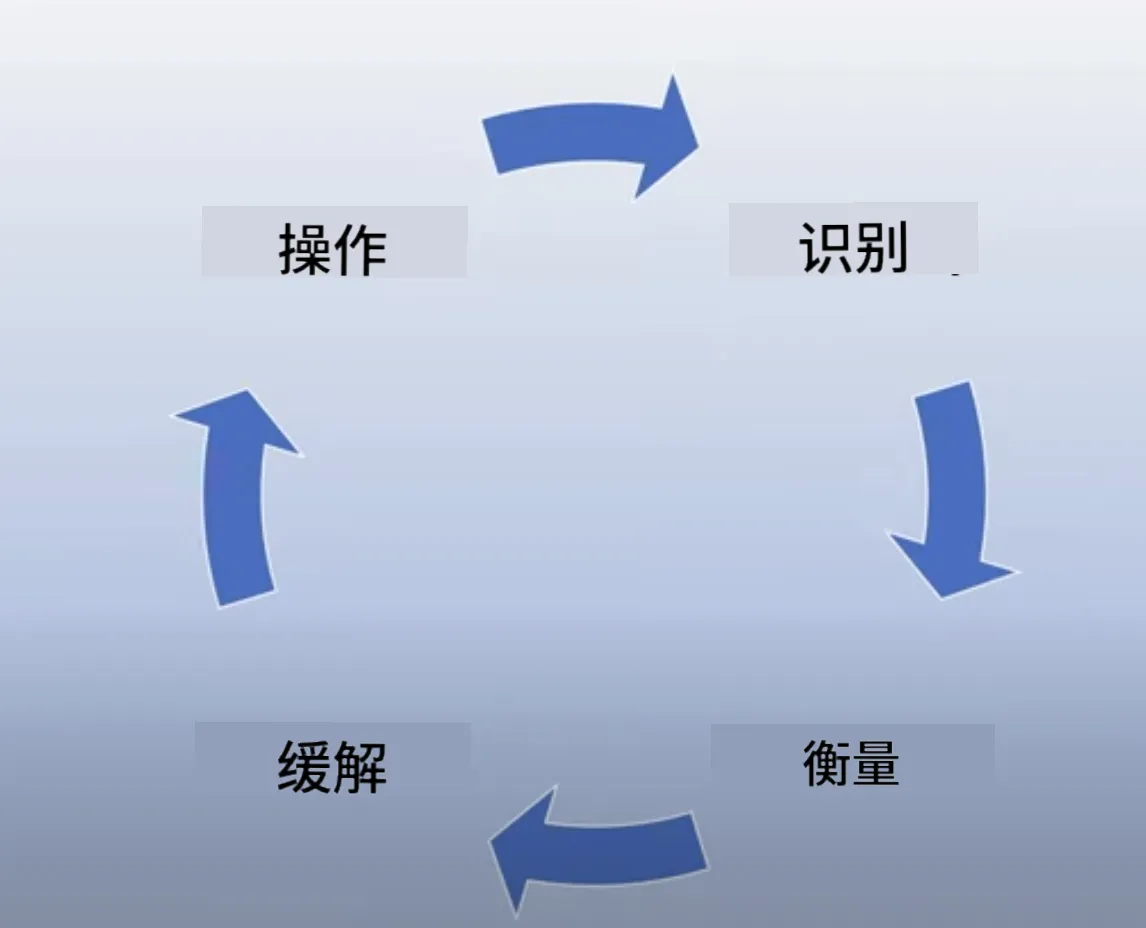
1. 评估潜在危害
模拟真实场景测试危害可能性:
- 教育类产品可准备学科知识、历史事件等提示词库
- 覆盖不同难度和敏感度的问题类型
2. 分层缓解机制
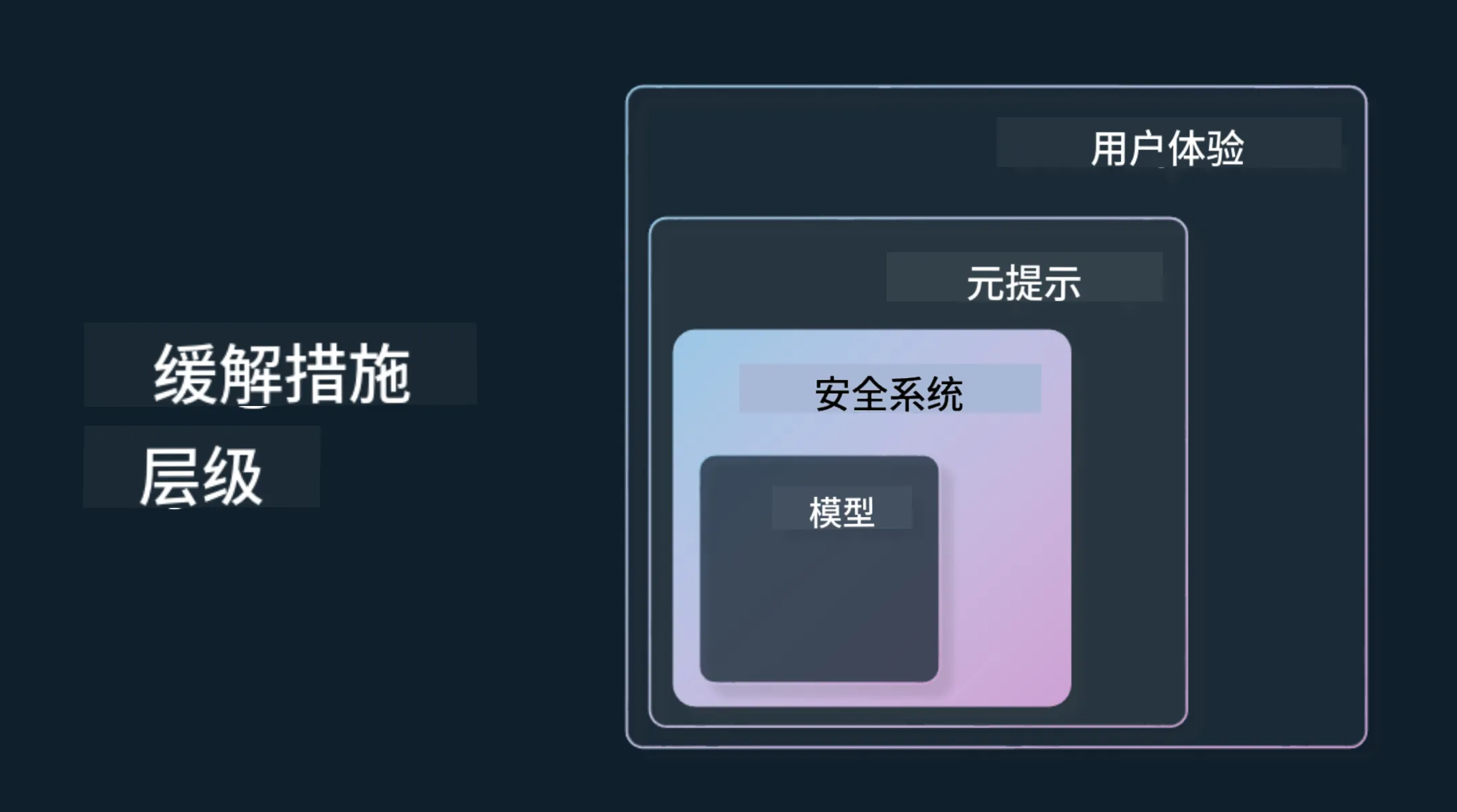
- 模型层
为场景选择匹配模型(如专用模型较通用模型风险更低),通过微调降低有害输出概率 - 安全系统层
部署内容过滤工具(如Azure OpenAI的内容安全系统),防御越狱攻击等异常行为 - 元提示层
通过系统提示限定模型行为(如:”你是一名教育助手,不得提供医疗建议”)
采用检索增强生成(RAG) 技术确保信息来源可信(详见搜索应用构建课) - 用户体验层
设计交互界面限制输入类型,明确告知AI能力边界(参见AI应用UX设计) - 持续评估
定期检测输出准确性、相关性等指标,建立用户信任
3. 构建责任运营体系
上线前需建立:
- 法律合规审查流程
- 安全事件响应机制
- 紧急回滚方案
- 持续监控策略
4. 善用工具生态
开发者可利用Azure AI Content Safety等工具,通过API快速检测有害内容。
🚀 实践挑战
探索Azure AI内容安全工具,设计适合你场景的防护方案。
视频教程
https://48673fs5cb16.vicp.fun/quanyouhulian/3、负责任地使用生成式 AI.mp4
视频内容介绍:
- 生成生成生成 AI 应用程序时应优先考虑负责任的 AI 的原因。
- 负责任的 AI 的核心原则及其与生成 AI 的关系。
- 如何通过策略和工具将这些负责任的 AI 原则付诸实践。
下节分享预告
第 4 课:理解提示工程基础,学习: 提示工程最佳实践的动手操作!