提示工程基础
上篇文章我们分享了负责任的使用生成式 AI(https://mp.weixin.qq.com/s/IU5X3ZlzT_iHG0OI9LAs2A),今天继续分享:提示词工程基础。
老规矩,分享前我们回顾下所有要分享的内容:
课程总览(两大阶段,循序渐进)
第一阶段:生成式 AI 入门(1-21)

第二阶段:AI Agent 学习(设计模式到生产实践)

本模块将带你了解为生成式AI模型打造高效提示的核心原则和实用技巧,你向大语言模型(LLM)提交提示的方式,直接决定着获得回复的质量。一份精心设计的提示,往往能换来更出色的输出结果,那么,究竟什么是提示词工程?如何优化发送给LLM的输入内容?这些疑问将在本章及后续章节中逐一揭晓。
生成式AI能够响应用户需求生成全新内容(如文本、图像、音频、代码等)。其核心支撑是像OpenAI的GPT系列(“生成式预训练变换器”)这样的大语言模型,这些模型经过海量自然语言和代码训练。
如今用户可通过熟悉的方式(如聊天界面)与这些模型交互,无需技术背景。模型采用提示驱动机制:用户发送文本输入(提示),AI返回响应(补全)。通过多轮对话调整提示,用户可不断优化回复效果。
“提示”已成为生成式AI应用的核心_编程接口,用于指导模型行为并影响输出质量。“提示工程”这个新兴领域,专注于研究如何设计和优化提示词以获取高质量输出。
核心目标
本课程将深入探讨提示工程的定义、重要性以及设计高效提示的方法。你将掌握提示工程的核心原理和最佳实践,并通过互动性Jupyter Notebooks沙盒环境实践操作。
学习目标
- 理解提示工程的概念与价值
- 掌握提示的关键构成与应用方法
- 学习提示工程的最佳实践技巧
- 运用OpenAI接口实践所学技巧
核心术语
- 提示工程:设计并优化输入内容,引导AI生成目标输出的实践
- 分词(Tokenization):将文本拆解为模型可处理的语义单元(token)的过程
- 指令微调LLM:通过特定指令训练优化,提升响应准确性的语言模型
实践沙盒
当前提示工程更像艺术而非精密科学。提升直觉的最佳方式是动手实践——通过迭代测试,结合领域知识与技巧优化模型输出。
本课程配备的Jupyter Notebook提供交互式沙盒环境,支持边学边练。运行前需准备:
- Azure OpenAI API密钥——用于访问LLM服务
- Python运行环境——执行Notebook代码
- 本地环境变量——立即完成环境配置
Notebook内置基础练习,更建议你添加自定_Markdown_说明和_代码_模块,尝试更多案例以培养提示设计直觉。
学习导图
先通过视觉导图把握课程脉络:从理解核心概念与挑战,到应用提示工程技巧应对问题。注意导图中“进阶技巧”部分将在第5课详解。

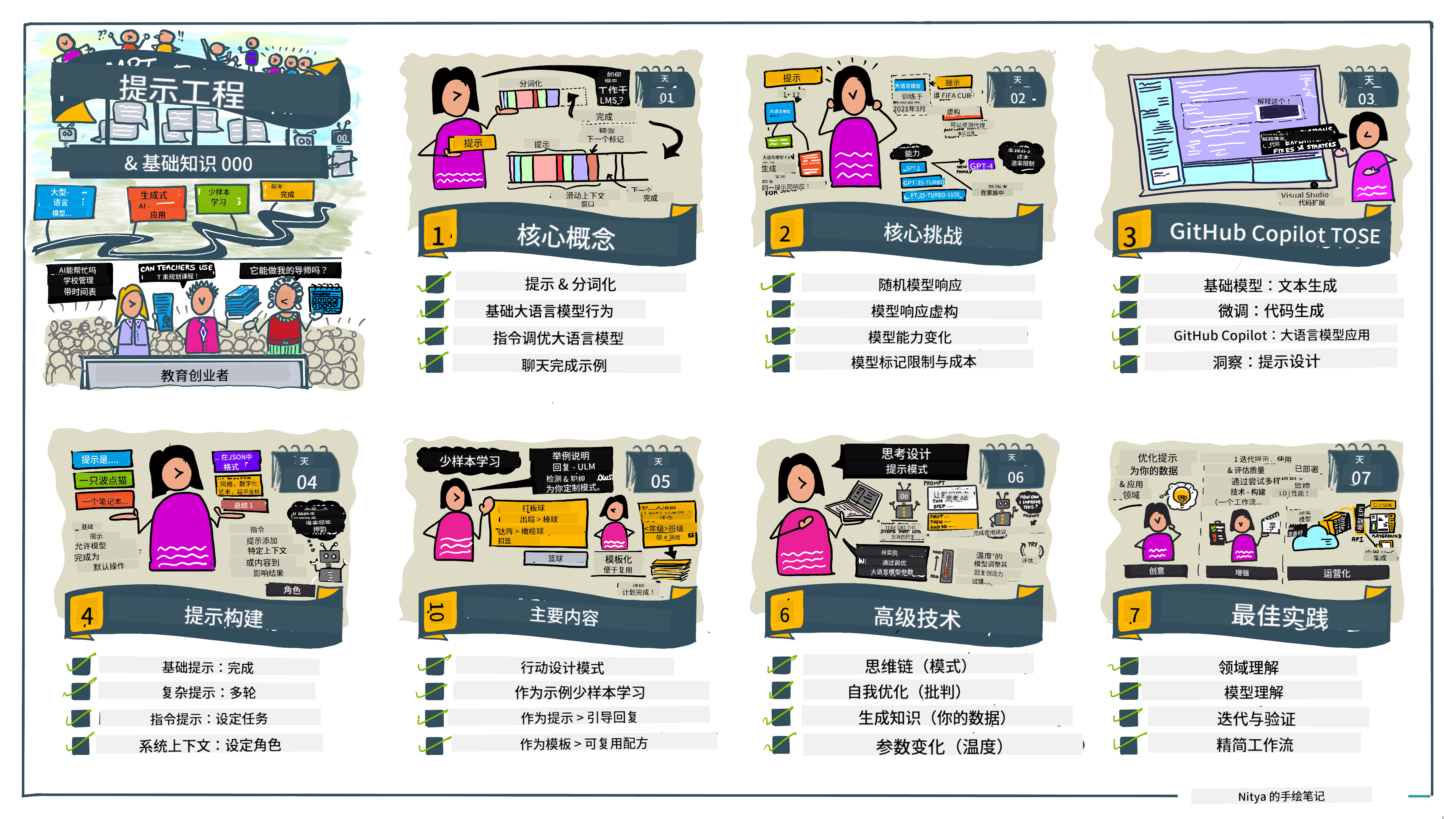
实战项目场景
如何将本课知识融入我们“赋能教育AI创新”的创业项目?设想打造AI驱动的个性化学习应用时,不同用户如何设计提示:
- 管理员:用AI分析课程数据缺口
→ 生成报告并可视化 - 教师:为特定学生群体定制教案
→ 按格式生成个性化方案 - 学生:获取解题辅导
→ 根据水平提供定制案例
访问**教育提示库**,获取教育专家整理的开源提示模板!尝试在沙盒或OpenAI Playground中运行体验。
什么是提示工程?
我们将提示工程定义为:针对特定模型和应用目标,通过_设计优化_文本输入(提示),获取高质量、一致性响应(补全)的过程。包含两个关键阶段:
- 为特定模型和目标_设计_初始提示
- 通过迭代_优化_提升输出质量
该过程依赖用户直觉与持续调试。理解其重要性需先掌握三个基础概念:
- _分词_:模型如何解析提示
- _基础LLM_:模型如何处理提示
- _指令微调LLM_:模型如何理解任务
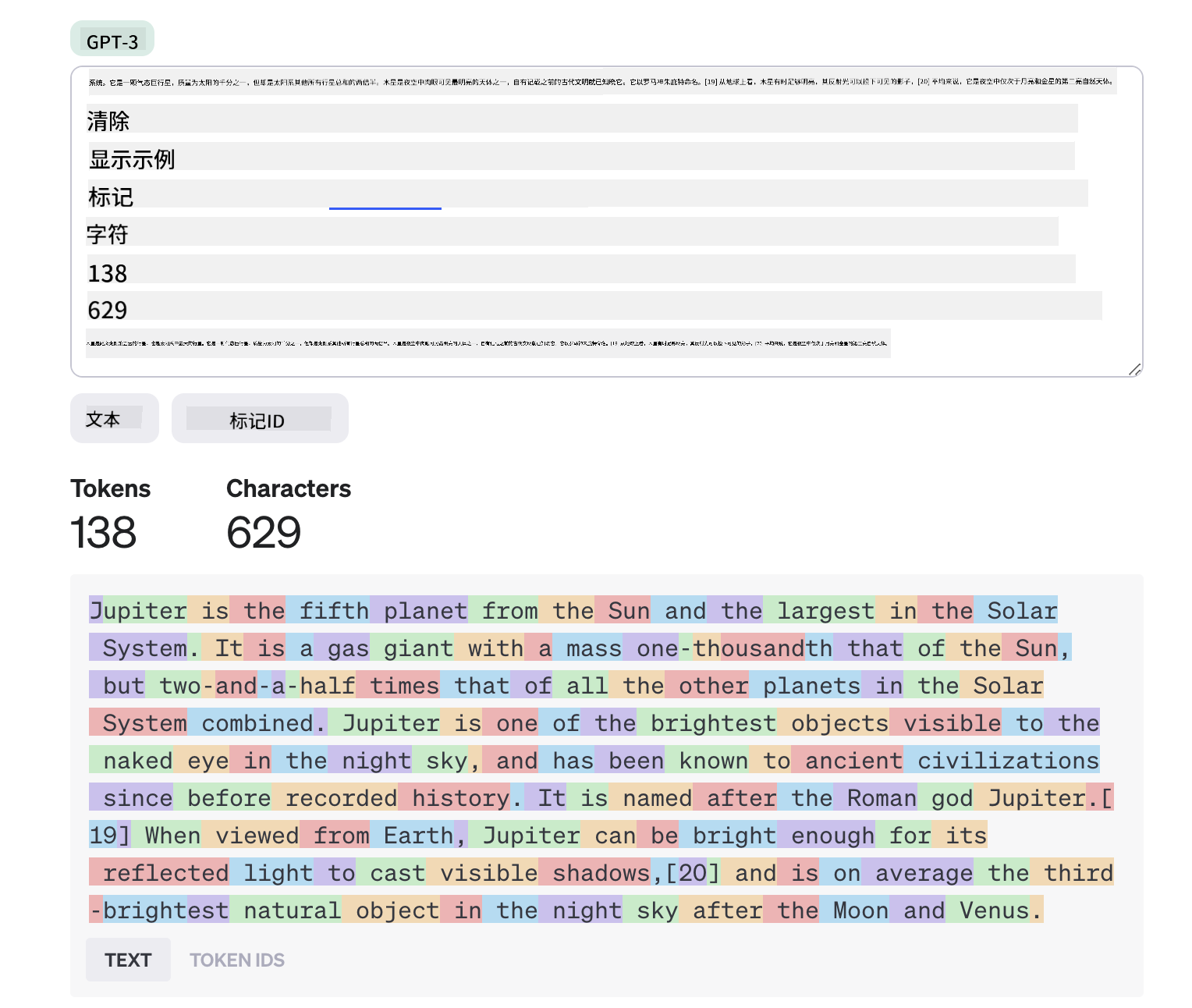
分词机制
LLM将提示视为_token序列_。不同模型对同一提示的分词方式不同,直接影响输出质量。推荐使用OpenAI分词器工具直观体验分词过程:

基础模型原理
提示被分词后,基础LLM的核心功能是预测序列中下一个token。模型通过海量文本训练掌握token间统计规律,从而进行概率预测。需注意:模型不理解语义,仅根据模式生成补全。
在Azure OpenAI Playground输入简单提示如“木星是…”,观察基础模型的补全结果:

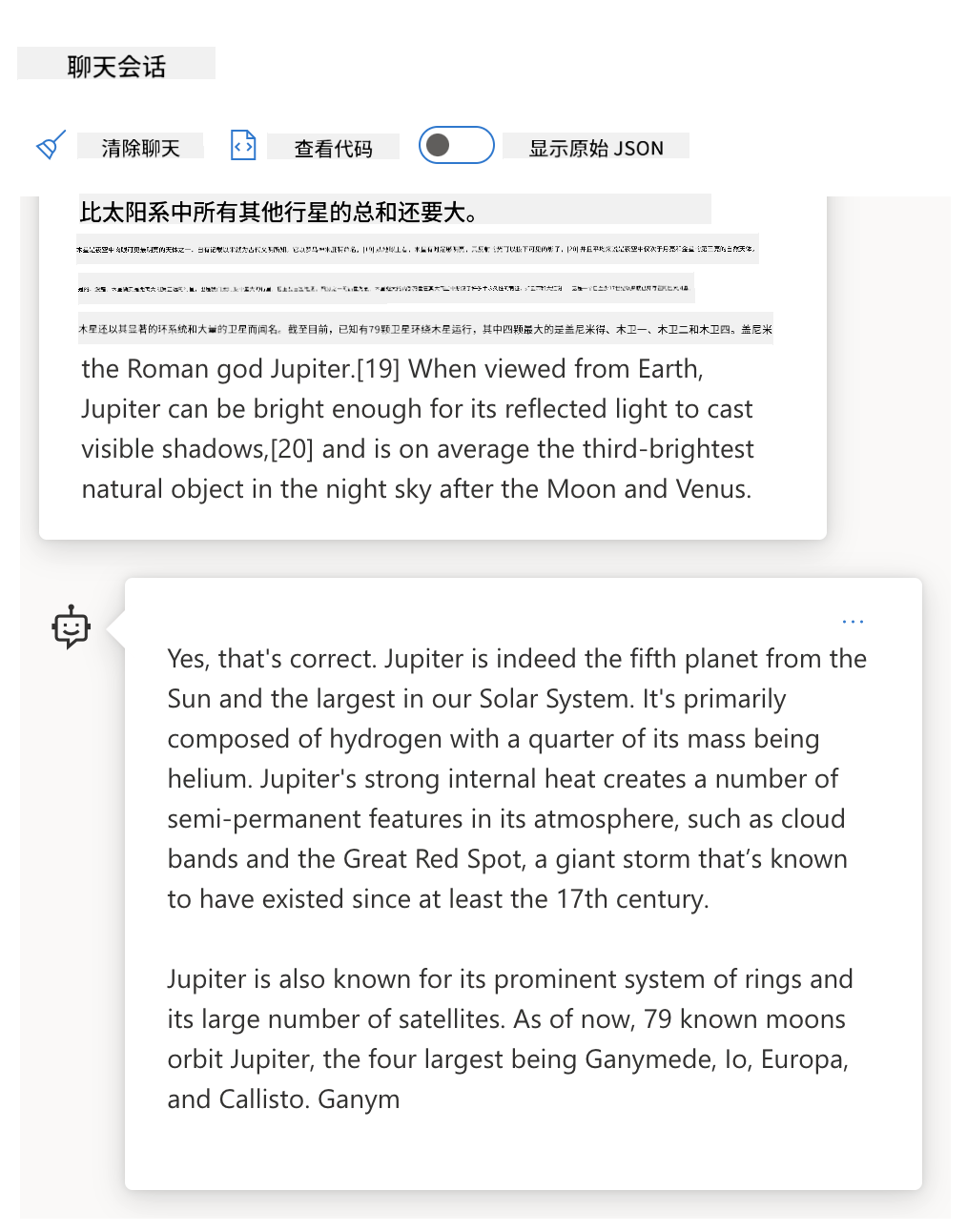
指令微调模型
指令微调LLM在基础模型上,通过含明确指令的示例(如对话记录)进行优化。采用RLHF(人类反馈强化学习)技术,训练模型_遵循指令_并适配用户目标。
将系统提示改为:“请为二年级学生总结以下内容,用1段话+3-5个要点”。观察优化后的响应如何直接用于课堂教学:


为什么需要提示工程?
理解LLM处理机制后,提示工程的必要性凸显于三大挑战:
- 输出随机性
相同提示在不同模型/版本下输出差异显著。提示工程通过约束条件减少波动 - 内容虚构风险
模型可能生成不准确内容。提示工程可要求提供引用或推理过程 - 模型能力差异
新模型能力更强但成本更高。提示工程可实现跨模型无缝适配
虚构内容验证
我们使用“虚构内容”指代LLM生成错误信息的情况(避免拟人化术语“幻觉”)。通过虚构主题提示测试:
1 | |
测试不同模型输出结果(均虚构时间线与事件):
| 模型平台 | 输出特征 |
|---|---|
| OpenAI | 生成八年级课程框架 |
| Azure OpenAI | 创建高中课程大纲 |
| Hugging Face | 输出详细战争描述 |

提示:通过_元提示_和_温度参数_等技术可降低虚构风险
提示构建方法
掌握基础后,我们来拆解提示的_构建逻辑_。
基础提示
仅发送文本无上下文。例如输入美国国歌首句,模型自动补全歌词:
| 提示 | 补全 |
|---|---|
| “哦,你可看见…” | “这是美国国歌《星条旗》首句,完整歌词为…” |
复杂提示
通过Chat Completion API构建多轮对话上下文:
1 | |
指令提示
通过文本明确任务要求:
| 指令类型 | 示例 | 输出特征 |
|---|---|---|
| 简单 | “写段内战描述” | 基础段落 |
| 进阶 | “描述内战并列出关键日期” | 段落+时间轴 |
| 结构化 | “用JSON格式输出内战关键事件” | 结构化数据 |
提示工程技巧
提升效果的核心方法:
提供示例
通过示例教会模型输出模式:
| 方法 | 提示示例 | 输出 |
|---|---|---|
| 零样本 | “太阳在照耀”翻译成西语 | “El Sol brilla” |
| 单样本 | “太阳在照耀”=>”El Sol brilla” “寒冷多风日”=> | “Día frío y ventoso” |
| 少样本 | 球员跑垒=>棒球 打出Ace=>网球 击出六分=>板球 扣篮=> | 篮球 |
提示词引导
提供开头片段引导输出方向:
1 | |
模板化提示
创建可复用的提示配方:
- 基础模板:OpenAI示例库
- 动态模板:LangChain占位符模板
- 领域专用:教育提示库
最佳实践
遵循黄金原则提升效果:
| 实践 | 说明 | 案例 |
|---|---|---|
| 选用最新模型 | 新模型能力更强但需评估成本 | GPT-4 > GPT-3.5 |
| 区分指令与上下文 | 用分隔符明确各部分权重 | 用—分隔系统指令 |
| 指令具体化 | 明确长度/格式/风格要求 | “生成3点JSON格式总结” |
| 示例+讲解 | 先指令后示例效果更佳 | 零样本→少样本过渡 |
| 设置备选方案 | 降低虚构内容概率 | “如无数据请返回:信息不足” |
提示:效果因模型/任务而异,需持续迭代优化
企业案例:GitHub Copilot
GitHub Copilot的演进展示提示工程如何驱动产品迭代:
- 2023年5月:提升代码理解能力
- 2023年6月:编写更优提示指南
- 2023年7月:超越Codex的新模型
知识巩固
Q:哪个提示更符合最佳实践?
A. 展示红色汽车图片
B. 展示沃尔沃XC90红色车型在悬崖边夕阳下的图片
C. 展示红色沃尔沃XC90图片
✅ 答案:B选项最佳,明确指定品牌+场景;C选项次之
✏️** 挑战**:
尝试补全提示:”展示红色沃尔沃”,观察模型补全效果并优化
下一步
掌握基础后,进入第5课学习:高级提示技巧!